

Mise à l’échelle de l’analytique embarquée auprès des clients : un guide pratique
Pourquoi l'analytique embarquée échoue à grande échelle si vous ne la concevez pas à l'avance
Le passage de l'ajout de graphiques à la livraison d'un produit analytique multi-tenant
L'analytique embarquée n'est plus un simple atout. Elle façonne désormais les revenus, la fidélisation et l'expérience client. Quelques graphiques dans un portail client peuvent sembler corrects. Mais cette même configuration commence à se fissurer lorsqu'elle sert des centaines de locataires, chacun avec des données, des règles d'accès et une image de marque différents.
C'est là le changement fondamental. Les équipes passent d'intégrations ponctuelles à une couche produit qui doit fonctionner dans de nombreux environnements clients. Le travail n'est pas seulement visuel. Il touche à la latence, l'isolation, la gouvernance et le contrôle des coûts.
C'est là que la planification compte. Les équipes SaaS qui traitent l'analytique comme un produit clé dès le premier jour avancent plus vite par la suite. Elles déploient sans accumuler de tickets de support, de tableaux de bord lents ou de failles de sécurité.
Pourquoi cela est important pour les utilisateurs de YellowfinBI et les chefs d'entreprise
Les utilisateurs de Yellowfin connaissent bien ce problème. Les équipes produit veulent une analytique embarquée qui semble native. Les équipes BI veulent du contrôle et moins de travail manuel. Les dirigeants veulent de l'adoption, du libre-service et des décisions plus claires.
Ce mélange crée un test pratique. La couche analytique peut-elle prendre en charge plus d'utilisateurs sans plus de chaos ?
Yellowfin répond à ce cahier des charges avec une analytique embarquée, des options en marque blanche et des fonctionnalités basées sur l'IA bien pensées telles que Ask Yellowfin, Code Assistant, AI NLQ, Assisted Insights et Signals. La valeur est simple. De meilleures réponses, moins de frictions et moins de temps passé à construire une pile BI sur mesure.
Ce que signifie vraiment le déploiement de l'analytique embarquée à grande échelle chez les clients
Des tableaux de bord à locataire unique aux expériences multi-tenants de niveau entreprise
Déployer l'analytique embarquée à grande échelle chez les clients signifie qu'une seule couche analytique sert de nombreux environnements clients. Chaque locataire peut avoir ses propres données, autorisations, mises en page et modèles d'utilisation. Le produit doit traiter ces différences comme étant la norme.
Une fois que la notion d'échelle entre en jeu, l'architecture change rapidement. L'isolation des locataires est importante. Tout comme les performances, la personnalisation et la gouvernance. Un tableau de bord qui fonctionne pour un client peut devenir un goulot d'étranglement pour des milliers.
Une analogie utile peut aider ici. L'intégration d'un tableau de bord est une vitrine. L'analytique embarquée à grande échelle est un réseau de franchises. La marque reste cohérente, mais chaque emplacement fonctionne avec des règles et une demande locales.
L'analyse de rentabilisation : adoption, fidélisation et nouveaux revenus
Ce n'est pas seulement une tâche informatique. L'analytique embarquée devient une partie du produit lui-même. Elle peut augmenter la fidélisation car les utilisateurs restent dans l'application pour obtenir des réponses. Elle peut également soutenir les parcours de vente incitative lorsque l'analytique fait partie d'un niveau premium.
Il y a un autre avantage. Une meilleure analytique réduit souvent le taux d'attrition car les clients tirent plus de valeur de la plateforme qu'ils utilisent déjà.
Yellowfin soutient ce modèle avec une analytique embarquée d'apparence native, des contrôles en marque blanche et un délai de mise sur le marché plus rapide.
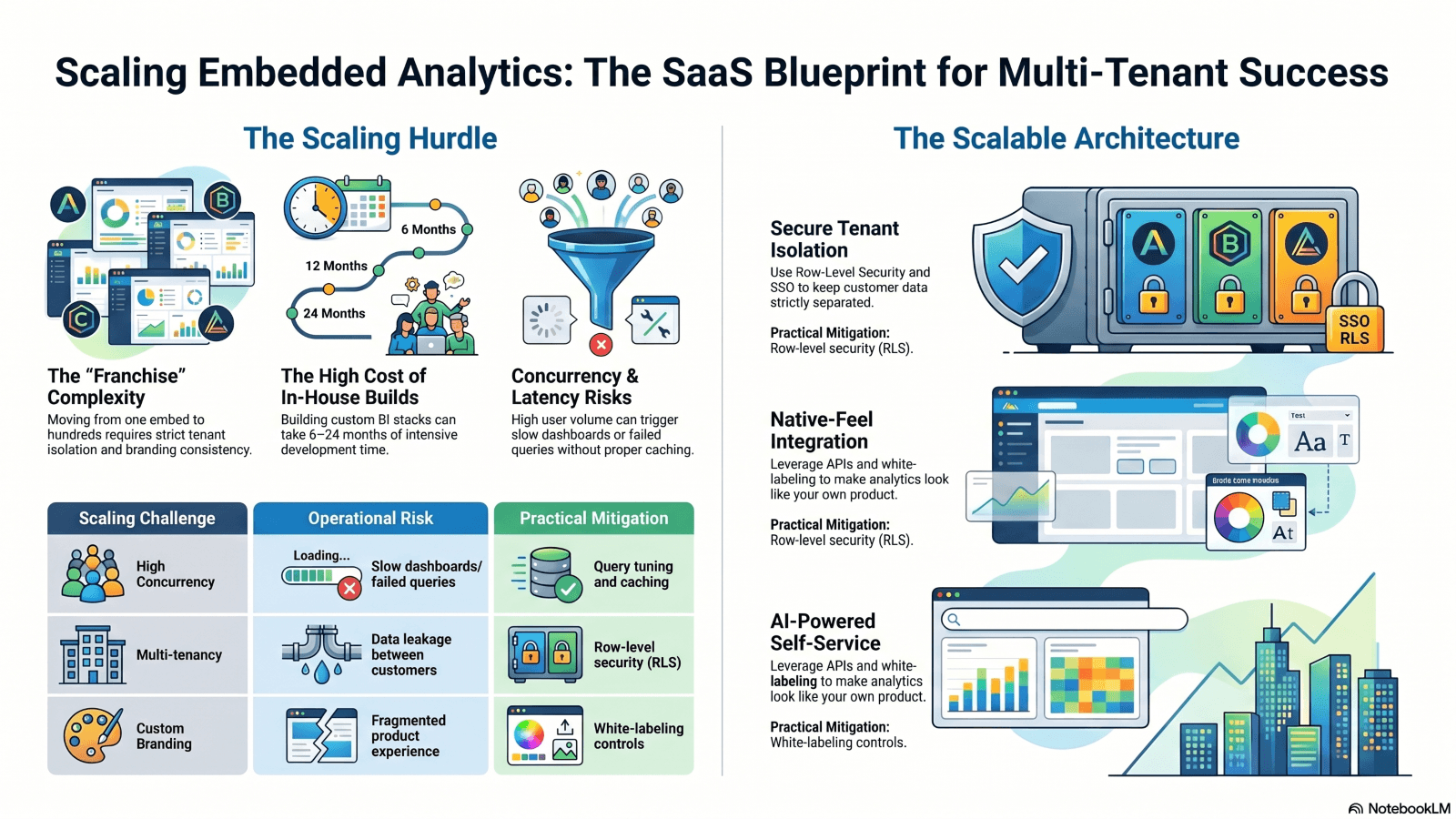
Les principaux défis liés au déploiement de l'analytique embarquée à grande échelle chez les clients
Performances, simultanéité et latence des requêtes
Dans les grandes organisations et les déploiements multi-tenants, il y a potentiellement des milliers d'utilisateurs qui tentent d'interroger des données en direct en même temps, en particulier lorsque quelque chose d'important est annoncé. Cette pression soudaine se manifeste dans les bases de données, les API et le rendu frontal. Même un bon tableau de bord peut ralentir lorsque tout le monde l'ouvre en même temps.
Les correctifs habituels s'appliquent toujours. Mettez en cache les requêtes répétées. Poussez le travail lourd vers des systèmes en colonnes. Séparez les charges de travail afin qu'un locataire n'en évince pas un autre.
Lorsque les équipes sautent ce travail, elles obtiennent des temps de chargement longs et des requêtes ayant échoué. Lorsqu'elles le planifient, les tableaux de bord restent utiles sous pression.
Multi-tenant, sécurité et personnalisation à grande échelle
L'isolation des locataires et l'infrastructure partagée tirent souvent dans des directions opposées. Cette tension se situe au centre de l'analytique multi-tenant. Les équipes de sécurité veulent des limites strictes. Les équipes produit veulent des services partagés et une livraison rapide.
Les bases sont claires. Utilisez la sécurité au niveau des lignes. Ajoutez le SSO. Conservez les journaux d'audit. Rendez les autorisations sensibles aux locataires. Ces contrôles comptent encore plus lorsque les clients s'attendent à un soutien en matière de conformité.
La personnalisation ajoute une autre couche. L'image de marque en marque blanche, les rôles personnalisés et les vues spécifiques aux locataires peuvent vite devenir désordonnés si chaque client obtient une version spéciale.
| Défi de mise à l'échelle | Risque opérationnel | Atténuation pratique |
| Forte simultanéité | Tableaux de bord lents, requêtes échouées | Mise en cache, optimisation des requêtes, configuration des données en direct |
| Architecture multi-tenant | Fuite de données entre les clients | Sécurité au niveau des lignes, autorisations par locataire |
| Image de marque personnalisée | Expérience produit fragmentée | Contrôles en marque blanche, paramètres de thème |
| Augmentation des coûts | Dépenses d'infrastructure imprévues | Surveillance de l'utilisation, contrôles de la charge de travail |
| Conformité | Lacunes d'audit et problèmes d'accès | SSO, journalisation, politiques de gouvernance |
Modèles d'architecture qui permettent à l'analytique embarquée de passer à l'échelle
Choix de la couche de données : en direct, en cache, fédérée ou hybride
Il n'y a pas de modèle de données unique qui convienne à tous les produits SaaS. Les requêtes en direct fonctionnent lorsque la fraîcheur des données est importante. L'analytique en cache fonctionne lorsque les utilisateurs exécutent souvent les mêmes rapports. L'accès fédéré aide lorsque les données se trouvent sur plusieurs systèmes. Un modèle hybride convient le mieux à de nombreuses équipes.
L'hybride est généralement le choix pratique. Il permet aux équipes d'utiliser des données en direct pour des vues opérationnelles, des données en cache pour la vitesse et un accès fédéré là où la duplication n'a aucun sens. Cet équilibre est courant dans la conception de l'analytique moderne.
La clé est de faire correspondre le modèle au cas d'utilisation, et non d'imposer la même forme à chaque tableau de bord.
Infrastructure orientée locataire et isolation de la charge de travail
Le trafic en « rafale » d'un client ne devrait pas ralentir tous les autres. C'est pourquoi une infrastructure sensible aux locataires est importante. Isolez les lourdes charges de travail. Utilisez la mise à l'échelle automatique dans la mesure du possible. Donnez aux gros clients leur propre bac à sable ou chemin de calcul si nécessaire.
Cela réduit les problèmes de voisinage bruyant et maintient les performances SLA stables. Cela permet également aux équipes SaaS de prendre en charge davantage de clients sans se diviser en de multiples piles BI distinctes.
Pour les utilisateurs de Yellowfin, cela signifie qu'une seule couche d'analytique embarquée peut servir de nombreux groupes de clients tout en restant stable et réactive.
| Modèle | Idéal pour | Avantages | Inconvénients |
| Requêtes en direct | Tableaux de bord opérationnels | Données fraîches, décisions rapides | Nécessite des ajustements et une infra solide |
| Analytique en cache | Cas d'utilisation répétés | Réponse rapide, coût réduit | Décalage dans la fraîcheur des données |
| Accès fédéré | Domaines de données distribués | Pas de duplication, large accès | Gouvernance plus difficile |
| Modèle hybride | Plateformes SaaS d'entreprise | Équilibre entre contrôle et performances | Nécessite une orchestration |
Comment Yellowfin aide les équipes à fournir une analytique embarquée qui semble native
Marque blanche, API et intégration produit transparente
L'adoption augmente lorsque l'analytique semble faire partie de l'application, et non comme un ajout externe. Cela signifie faire correspondre l'apparence et le comportement du produit hôte. Yellowfin prend cela en charge grâce à une intégration JavaScript légère et des options d'iframe sécurisées, ainsi que des contrôles en marque blanche pour l'image de marque. Les développeurs Delphi, C++, Java et .Net peuvent également facilement intégrer Yellowfin et, en utilisant les capacités de marque blanche incluses, ils peuvent obtenir un aspect totalement fusionné, en en faisant véritablement partie de leurs propres applications.
Cela compte pour les utilisateurs également. Lorsque la couche analytique s'adapte au produit, la confiance augmente et les questions d'assistance diminuent. Les équipes passent moins de temps à expliquer où s'arrête l'application et où commence l'outil de BI.
La position de Yellowfin en matière d'analytique embarquée est construite autour de cette idée, avec une analytique qui semble native au produit. C'est une victoire pratique pour les équipes SaaS qui se soucient de la vitesse et de la qualité du produit.
Analytique conversationnelle et libre-service alimentés par l'IA à grande échelle
L'IA réduit la charge de travail des équipes d'analytique. « Ask Yellowfin », l'Assistant de code, l'IA NLQ, les Assisted Insights et les Signals permettent aux utilisateurs métiers de poser des questions sans attendre un spécialiste.
Cela réduit la dépendance à l'égard des analystes et raccourcit le chemin de la question à la réponse. Cela donne également aux équipes produit un récit plus solide en matière de libre-service.
Yellowfin 9.17 ajoute davantage de capacités basées sur l'IA pour les cas d'utilisation conversationnels. Cela a de l'importance lorsque des milliers d'utilisateurs ont besoin de réponses rapides, et non d'une énième file d'attente pour des demandes de rapports.
La gouvernance, la sécurité et la conformité doivent également évoluer à grande échelle
Instaurer la confiance avec SSO, RBAC, RLS et l'auditabilité
Une configuration d'analytique embarquée à grande échelle nécessite un contrôle d'accès de niveau entreprise. Le SSO simplifie la connexion. L'authentification basée sur JWT aide au contrôle des sessions. Le contrôle d'accès basé sur les rôles (RBAC) définit qui peut voir quoi. La sécurité au niveau des lignes (RLS) sépare les données des locataires. Les journaux d'audit fournissent aux équipes un enregistrement de qui a fait quoi.
Ces contrôles ne sont pas des extras. Ils sont inclus en tant que partie intégrante du produit.
Éviter le piège du tableau de bord partagé et du risque partagé
Un tableau de bord partagé peut devenir un risque partagé si le modèle de sécurité est faible. Une mauvaise règle d'autorisation peut exposer les données à travers les locataires. Une piste d'audit faible peut créer un désastre de conformité.
Ce risque augmente rapidement dans les secteurs réglementés. Les équipes de la finance, de la santé, des télécommunications et du secteur public ont besoin de limites claires et d'un accès traçable. Le modèle de déploiement d'entreprise de Yellowfin répond à ce besoin en prenant en charge un accès contrôlé et une analytique gouvernée à grande échelle.
Contrôle des coûts et efficacité opérationnelle pour une mise à l'échelle à long terme
Économie prévisible basée sur l'utilisation plutôt que sur des coûts d'infrastructure hors de contrôle
L'analytique embarquée peut devenir coûteuse lorsque le volume des requêtes croît plus vite que prévu. La solution commence par les modèles d'utilisation. Surveillez la fréquence des requêtes. Ajustez les caches. Définissez des politiques de rétention. Mesurez l'utilisation d'une manière qui correspond à la valeur, et pas seulement au nombre de sièges.
Ce modèle maintient le coût lié à la consommation réelle. Il aide également les équipes produit à expliquer l'économie à la direction avec moins de conjectures.
Yellowfin aide les équipes à éviter de créer et de maintenir une pile analytique personnalisée à partir de zéro, ce qui réduit à la fois la charge d'ingénierie et les frais généraux à long terme.
Où l'automatisation offre le meilleur retour sur investissement
Les meilleures cibles d'automatisation sont les tâches répétitives. Le provisionnement. Les changements d'autorisations. Les actualisations de tableaux de bord. Le routage des alertes. Ces tâches s'accumulent rapidement à grande échelle.
La mise à l'échelle prédictive et les modèles sans serveur (serverless) aident également là où le trafic change par locataire ou par moment de la journée. Le résultat est des opérations plus simples et un contrôle de marge plus net.
Un cadre étape par étape pour déployer l'analytique embarquée à grande échelle chez les clients
Commencez par le cas d'utilisation client à plus forte valeur ajoutée
Commencez par un ou deux flux de travail qui comptent le plus. Choisissez le tableau de bord ou le rapport que les utilisateurs consultent souvent et dont les dirigeants se soucient.
Définissez ensuite les chiffres qui comptent. L'adoption. Le temps de compréhension (Time to insight). Le temps de réponse aux requêtes. Le volume de support. Si ces mesures vont dans la bonne direction, le déploiement est sur la bonne voie.
Standardisez, puis personnalisez
L'ordre intelligent est simple. Construisez d'abord un noyau partagé. Ajoutez ensuite de la flexibilité au niveau du locataire là où c'est important.
Un bon parcours de déploiement ressemble à ceci :
- Modèle de données de base
- Gouvernance et autorisations
- Image de marque et couche d'intégration
- Fonctionnalités d'IA et de libre-service
- Surveillance de l'utilisation et optimisation
Cette séquence maintient la base stable tout en laissant de la place aux besoins spécifiques des clients.
Déployez l'analytique embarquée à grande échelle sans sacrifier la vitesse, la confiance ou l'expérience
Points clés à retenir pour les leaders du SaaS et les équipes analytiques
Déployer l'analytique embarquée à grande échelle chez les clients nécessite plus que l'ajout de graphiques. Cela nécessite une mentalité de produit, une gouvernance claire, l'isolation des locataires, de solides performances et le contrôle des coûts. Les équipes qui planifient ces éléments à l'avance évitent des reconstructions douloureuses plus tard.
Yellowfin correspond bien à ce modèle. Il offre aux équipes SaaS de l'analytique embarquée, des insights pilotés par l'IA, une flexibilité en marque blanche et une fiabilité à l'échelle de l'entreprise en un seul endroit.
Et ensuite ?
Découvrez les dernières fonctionnalités basées sur l'IA dans Yellowfin 9.17.
Téléchargez L'Alternative à Power BI : Guide de migration vers Yellowfin.
Essayez Ask Yellowfin et Code Assistant.
Demandez une démo ou essayez Yellowfin et découvrez comment l'analytique embarquée peut être déployée à grande échelle chez les clients.