

Gevoelige gegevens in business analytics: on-premises hosting met analytics die de gebruikersstroom niet onderbreken
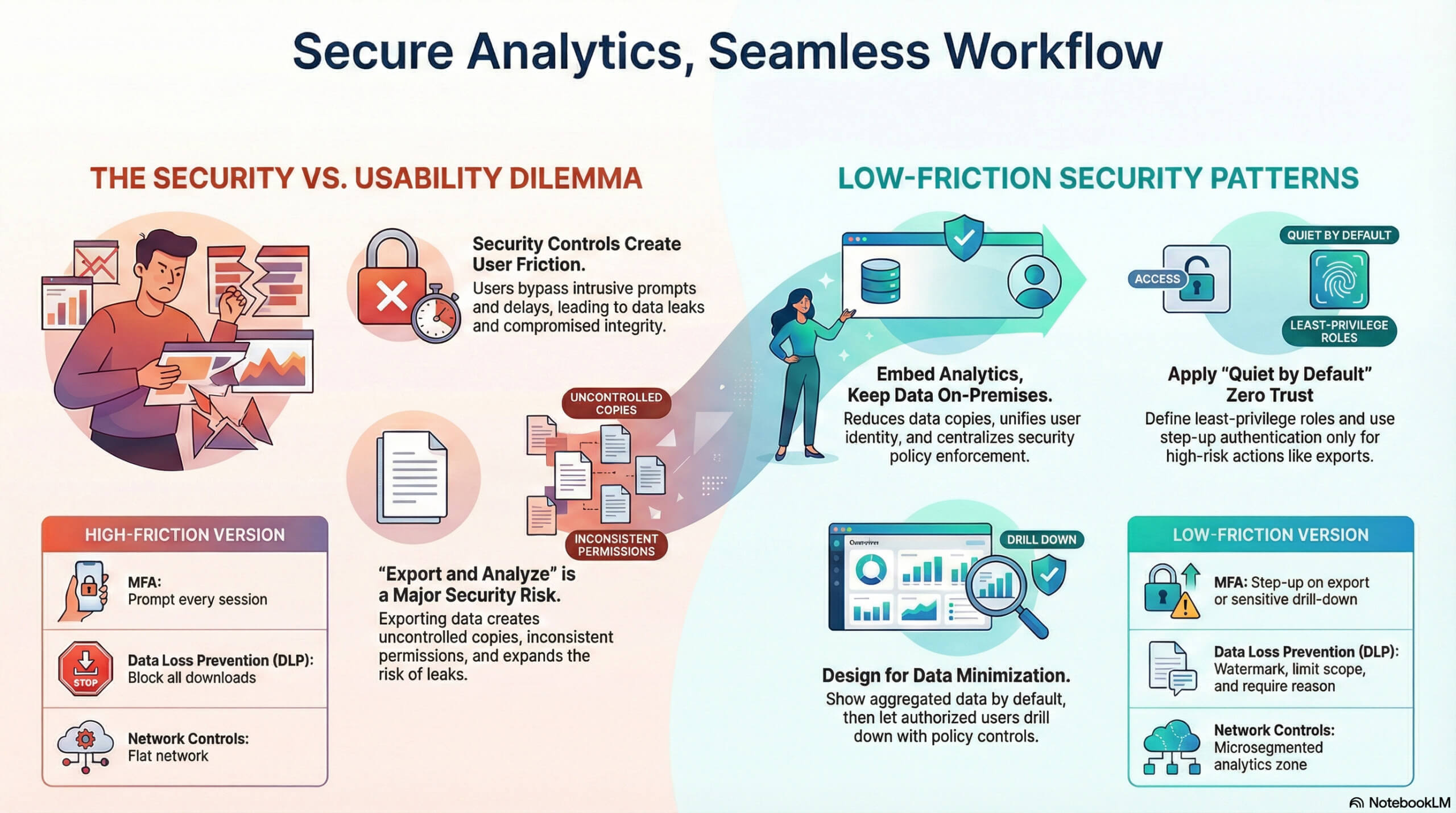
Leidinggevenden lijken soms twee dingen tegelijk te willen. Snelle antwoorden binnen operationele tools én strikte controle over gevoelige data in bedrijfsanalyses (business analytics). Het probleem is wrijving. Veel beveiligingscontroles voegen prompts, vertragingen en geblokkeerde schermen toe. Gebruikers werken eromheen of ontwikkelen een "spiergeheugen" waarbij ze op een knop klikken zonder de betekenis van de tekst die ze zien volledig in zich op te nemen - of zelfs zonder deze bewust te hebben gezien. Als u even terugdenkt, klinkt dit u dan bekend in de oren? Analisten exporteren naar spreadsheets; dat is vaak nog steeds hun favoriete wapen. Leiders kunnen het vertrouwen in de cijfers verliezen als het verhaal dat ze vertellen niet ook wordt ondersteund door geloofwaardige feiten. Erger nog als die feiten vervuild of gecompromitteerd zijn.
Beveiliging gaat over meer dan alleen het voorkomen van datalekken en zorgen dat data niet in de verkeerde handen valt; het gaat ook om het waarborgen van de integriteit van de aangeleverde data, de waarheden waarop uw BI-verhaal en analyses zijn gebouwd. Maar het waarborgen van die zekerheid van feitelijke data mag de consumptie en het gebruik ervan niet onnodig belemmeren door de toegepaste beveiligingsmethoden te zwaar te maken - en dat is het lastige gedeelte: balans en effectiviteit.
De oplossing is niet "minder beveiliging". Het is beveiliging die aansluit bij de intentie van de gebruiker en het risico, met controles die zich het grootste deel van de tijd op de achtergrond bevinden. On-premises hosting helpt hierbij, omdat het kritieke datasets, sleutels en beleidshandhaving dicht bij de bronsystemen (systems of record) houdt. Het vermindert ook de blootstelling van data aan derden en de impactradius (blast radius) van leveranciers. Wanneer de balans juist is, is de beveiliging ingebakken, effectief, alomtegenwoordig, maar vrijwel onmerkbaar.
Eén vraag is belangrijker dan de rest: hoe kunnen analyses binnen de workflow van de gebruiker blijven, terwijl de beveiliging strikt blijft?
Houd analyses in het product, data on-premises
Ingebedde (embedded) analyses winnen het van "exporteren en analyseren"
De gebruikersflow wordt onderbroken wanneer analyses zich op een afzonderlijke locatie bevinden. Het wisselen van tools zorgt voor extra inlogprompts, andere rechten, andere filters en meer exports. Exports creëren kopieën, en kopieën creëren lekken.
Een veiliger patroon zijn ingebedde analyses binnen dezelfde applicatie waar gebruikers werken. Dat levert drie concrete voordelen op voor gevoelige data in bedrijfsanalyses:
- Minder datakopieën. Berekeningen vinden plaats dicht bij de bron en de resultaten stromen naar de gebruikersinterface (UI).
- Consistente identiteit. Dezelfde gebruikersidentiteit controleert zowel acties als analyses.
- Beleidshandhaving op één plek. Beveiligingsregels zijn van toepassing op zowel transacties als query's.
On-premises hosting beperkt ook wat een externe aanbieder van analyses kan zien. Toegang door leveranciers wordt een uitzondering, niet de standaard. Dat is belangrijk omdat supply chain- en derdenrisico's een terugkerend thema zijn in cyberrichtlijnen, waaronder de voorspellingen voor 2026 gepubliceerd door Morrison Foerster.
Ontwerpdoel: onzichtbare controles, zichtbare verantwoordelijkheid
Beveiligingsteams meten vaak de kracht van de controle die ze hebben over de dreigingen. Gebruikers meten de onderbrekingen van hun gewenste resultaten of de frustraties bij het bereiken van hun doelen. Het juiste doel is "standaard stil" (quiet by default), met sterk bewijs wanneer er iets misgaat of mis is gegaan. Het is niet genoeg om een "onderbuikgevoel" te hebben dat er iets niet klopt.
Dat komt overeen met de verschuiving naar adaptieve, beleidsgestuurde datacontroles, zoals beschreven in de trenddiscussie voor 2026 over uniforme databescherming en automatisering van Cyberhaven.
Gevoelige data in bedrijfsanalyses: Zero Trust zonder constante prompts
Continue verificatie, minste privileges (least privilege), microsegmentatie
Zero Trust is zeer geschikt voor analyses, omdat query-toegang een pad met een hoog risico is. Een enkele analist kan sneller miljoenen rijen ophalen dan welk app-scherm dan ook. Simpel gezegd betekent de mogelijkheid om op uitgebreide wijze toegang te krijgen tot de ruwe data een uitbreiding van mogelijk misbruik van die data, en ook een risico voor de waarheid ervan als onbelemmerde mogelijkheden om deze te wijzigen worden gegeven zonder het juiste niveau van toezicht.
Pas Zero Trust toe op manieren die de flow niet onderbreken:
- Query-rollen met de minste privileges. Definieer rollen per taak, niet per functietitel. Scheid "KPI-kaarten bekijken" van "details op rijniveau exporteren".
- Microsegmentatie voor analysediensten. Isoleer de query-engine van operationele netwerken. Beperk oost-westverkeer.
- Risicogebaseerde opschaling (step-up) alleen wanneer nodig. Voeg geen MFA-prompts toe aan elke grafiekweergave. Activeer step-up bij het exporteren, het verbreden van selectiebereiken of toegang tot gereguleerde velden.
Dit sluit aan bij algemene Zero Trust-richtlijnen, waaronder identiteitsverificatie, minste privileges en segmentatie zoals beschreven in de Zero Trust-inzichten van Archtis.
UX-patroon: stapsgewijze vrijgave (progressive disclosure) van gevoelige details
De meeste gebruikers hebben geen ruwe identificatiegegevens nodig. Geef ze standaard aggregaties, en laat geautoriseerde gebruikers daarna inzoomen (drill-down). De drill-down wordt het "controlepunt" voor step-up autorisatie, het opvragen van rechtvaardigingsopmerkingen of een tijdelijke toegangstoewijzing.
Dit helpt om dashboards snel te houden en vermindert blootstelling van gevoelige gegevens tijdens normale werkzaamheden.
Dataminimalisatie die nog steeds beslissingen ondersteunt
Verklein het blootstellingsoppervlak door het ontwerp
Dataminimalisatie is geen slogan. Het is een ontwerpspecificatie.
Voor gevoelige data in bedrijfsanalyses ziet minimalisatie er als volgt uit:
- Metriek-eerst modellering (Metric-first modeling). Bereken bedrijfsstatistieken vooraf uit gevoelige bronnen, sla waar mogelijk alleen afgeleide waarden op.
- Standaard naar cohorten en bereiken. Toon bandbreedtes, percentielen en aantallen, en sta vervolgens drill-down toe met controles.
- Korte bewaartermijn voor queryresultaten. Cache aggregaties voor snelheid, maar laat ze snel verlopen en versleutel de gecachte data.
Dit komt overeen met de basisprincipes van databeveiliging, zoals het beperken van verzameling en het beperken van toegang, zoals samengevat in de best practices voor databeveiliging van Palo Alto Networks en ook in overzichten zoals de Coursera primer voor databeveiliging.
Tabel: minimalisatiekeuzes die de workflow beschermen
| Ontwerpkeuze | Wat gebruikers zien | Beveiligingswinst | UX-winst |
| Geaggregeerde dashboards eerst | KPI's, trends, waarschuwingen | Minder blootstelling van ruwe data | Sneller laden, minder filters |
| Gevoelige velden standaard gemaskeerd | Gedeeltelijke identifiers | Verlaagt insider-risico | Minder afschrikwekkende waarschuwingen |
| Drill-down beveiligd door beleid | Details alleen wanneer nodig | Sterk controlepunt | Prompts verschijnen zelden |
| Doelgebonden exports | Exporteren met reden, reikwijdte | Beter audittrail | Duidelijkere intentie van de gebruiker |

Gevoelige data in bedrijfsanalyses: Realtime classificatie en routering op basis van gevoeligheid
Eén keer classificeren, overal handhaven
Classificatie faalt wanneer het afhankelijk is van handmatige tags. Analysepijplijnen verwerken data uit vele systemen en de gevoeligheid verandert bij het samenvoegen (joins). Realtime classificatie en beleidscontroles verminderen fouten.
Een praktisch on-prem patroon:
- Classificeer velden bij opname (ingestion). Tag kolommen als openbaar, intern, vertrouwelijk, gereguleerd.
- Koppel tags aan afstamming (lineage). Wanneer datasets combineren, moet de gevoeligheid volgen.
- Routeer op basis van gevoeligheid. Gereguleerde data blijft in strenger gecontroleerde opslag en rekenpools.
- Render op basis van gevoeligheid. De UI gebruikt dezelfde tags om te beslissen wat een rol mag zien.
Dit ondersteunt de beweging naar uniforme, geautomatiseerde bescherming en snelle handhavingscycli zoals besproken in de trends voor 2026 van Cyberhaven.
UX-patroon: "veilige standaarden" met snelle uitzonderingen
Gebruikers zouden geen gevoeligheidsniveaus moeten kiezen. Het product zou dat moeten doen. Wanneer uitzonderingen nodig zijn, gebruik dan een strakke flow: een klein justificatievakje, een kortdurende toewijzing en zichtbare logging.
Continue beoordeling van blootstelling voor analyse-oppervlakken
Test de datatrajecten, niet alleen de hosts
Analyses, vooral analyses van derden, creëren nieuwe aanvalsoppervlakken: query-API's, semantische lagen, gecachte resultatenopslag, export-endpoints en inbeddingstokens (embed tokens). De beoordeling van blootstelling moet zich daarop concentreren.
Ingebedde analyses bieden uiteraard een veel kleiner blootstellingsoppervlak vergeleken met externe oplossingen van derden. Yellowfin implementeert een grondig beveiligingsmodel om uw bedrijfsdata vanuit meerdere hoeken te beschermen, inclusief op rollen gebaseerde toegang en encryptie in rust en tijdens transport.
Praktische stappen:
- Scan analyse-API's op defecte autorisatie op objectniveau.
- Test inbeddingstokens op replay- en scope-misbruik.
- Controleer of caches gereguleerde velden niet als platte tekst opslaan.
- Valideer beveiliging op rij- en kolomniveau bij joins.
Tabel: veelvoorkomende analysecontroles en hun "wrijvingsarme" (low-friction) vorm
| Controle | Versie met veel wrijving | Versie met weinig wrijving |
| MFA | Prompt bij elke sessie | Step-up bij export of gevoelige drill-down |
| DLP | Blokkeer alle downloads | Watermerk, bereik beperken, loggen, reden vereisen |
| Netwerkcontroles | Plat netwerk | Gemicrosegmenteerde analysezone |
| Logging | Handmatige audits | Automatische vastlegging van bewijs naar compliance-dashboards |
Encryptie en Post-Quantum Planning zonder latentieverrassingen
Versleutel data in rust, tijdens transport en in de cache
On-prem betekent niet "veilig door locatie". Het betekent dat ú controle heeft over sleutels, netwerken en beleid. Versleutel:
- In rust in warehouses, lakehouses en semantische stores.
- Tijdens transport voor queryverkeer en inbeddingsverbindingen.
- In caches waar prestatieteams vaak de kantjes er vanaf lopen.
Algemene richtlijnen noemen consequent encryptie en sterke protocollen als kerncontroles, inclusief de samenvatting van best practices van Palo Alto Networks.
Begin voor langlevende gevoelige data in bedrijfsanalyses met het plannen van post-quantum gereedheid. Behandel het als een roadmap-item dat is gekoppeld aan bewaartermijnen van data en sleutelrotatie, niet als een plotselinge herbouw. Strategiediscussies voor 2026 plaatsen post-quantum planning vaak naast bredere beschermingsprogramma's, inclusief de planningsgerichte begeleiding in de databeschermingsstrategieën voor 2026 van Hyperproof.
Gedragsanalyses die misbruik detecteren zonder echt werk te blokkeren
Baselines per rol, niet per gebruiker
Analisten verkennen. Dat is hun werk. Anomaliedetectie moet dus rolpatronen begrijpen.
Goede signalen:
- Plotselinge verschuiving van aggregaties naar ruwe identificatiegegevens.
- Query's die ongebruikelijke business units omvatten.
- Snelle paginering of export-loops.
- Nieuwe tools of clients die de query-API aanroepen.
Pas vervolgens reacties toe die de flow intact houden:
- Zachte waarschuwingen in het product.
- Just-in-time her-authenticatie voor gevoelige acties.
- Limieten op exportfrequentie (rate limits), niet op grafieken.
Dit sluit aan bij de druk vanuit de sector naar contextbewuste controles en adaptieve beslissingen die worden besproken in verschillende overzichten van beveiligingstrends voor 2026, waaronder Cyberhaven en de bredere trendkadering van de Tarian Group.
Audit-Ready Compliance die geen handmatig werk oplevert
Maak bewijsvoering automatisch
Compliance-werk kan vaak de flow onderbreken voor zowel gebruikers als engineers. De oplossing is automatische bewijsvastlegging:
- Log elke toegang tot een gevoelig veld met gebruiker, rol, apparaat en doel.
- Sla query-vingerafdrukken (fingerprints) op, niet de volledige querytekst, voor het geval de tekst letterlijke waarden (literals) bevat.
- Registreer beleidsbeslissingen, inclusief weigeringen en step-up triggers.
Dit ondersteunt "audit per query" in plaats van "audit per spreadsheet". Compliance-automatisering is een terugkerend thema in op governance gerichte beveiligingsrichtlijnen, waaronder de gestructureerde controle-aanpak beschreven in Hyperproof.
Leveranciers- en derdenrisico wanneer data on-premises blijft
Behandel leverancierstoegang als een gecontroleerde, gelogde workflow
Externe aanbieders van analyses vragen vaak om data-extracten of directe connectoren. Dat creëert nieuwe kopieën, nieuwe inloggegevens en nieuwe juridische risico's.
Als gevoelige data in bedrijfsanalyses on-premises moet blijven:
- Geef de voorkeur aan ingebedde analyses die binnen uw eigen grenzen draaien.
- Als een leverancier toch verbinding moet maken, beperk deze dan tot een gesegmenteerde netwerkzone.
- Gebruik kortlopende inloggegevens en serviceaccounts met een beperkt bereik (scoped).
- Beoordeel API-scopes en roteer sleutels volgens een vast schema.
Verwachtingen rondom regelgeving en kritieke infrastructuur wijzen steeds meer op sterker toezicht en controle van leveranciers, zoals opgemerkt in de cyber- en privacyvoorspellingen voor 2026 van Morrison Foerster.

Een praktische bouwchecklist voor analyses die in de flow blijven
Gebruik dit als een implementatieleidraad voor on-prem analyses die gevoelige data verwerken:
- Plaats analyses binnen de UI van het operationele product.
- Kies standaard voor aggregaties, scherm details af met beleid.
- Handhaaf beveiliging op rij- en kolomniveau in de query-laag.
- Classificeer data bij opname, neem tags mee doorheen de data-afstamming (lineage).
- Versleutel opslag, transport en caches. Houd sleutels on-premises onder controle.
- Voeg alleen step-up auth toe voor risicovolle acties, zoals exporteren.
- Voer continue blootstellingstests uit op query-API's en inbeddingspaden.
- Log beleidsbeslissingen en toegangsevents tot gevoelige data automatisch.
- Behandel toegang van leveranciers als zeldzaam, afgebakend en volledig gelogd.
On-premises hosting is geen nostalgie. Het is een keuze voor controle. In combinatie met ingebedde analyses en wrijvingsarme beveiligingspatronen stelt het teams in staat om snel inzichten te leveren zonder dat gevoelige data in bedrijfsanalyses in een constante risicoafweging verandert.
FAQ (Veelgestelde vragen)
Hoe zijn Zero Trust-principes specifiek van toepassing op de autorisatie van analyse-query's zonder legitieme analyses te blokkeren?
Pas query-rollen met de minste privileges toe per taak, isoleer de analyse/query-laag via microsegmentatie en gebruik alleen risicogebaseerde step-up voor acties met een hoger risico (exports, bredere scopes, gereguleerde velden), niet voor het routinematig bekijken van dashboards.
Welke wettelijke vereisten (AVG/GDPR, HIPAA, SOX) hebben het meest directe effect op de omgang met on-premises analysedata?
In de praktijk sturen deze het meest direct aan op: strikte toegangscontroles (rij/kolom-niveau waar nodig), encryptie in rust/tijdens transport/in cache, geminimaliseerde/standaard geaggregeerde weergaven, gecontroleerde exports en geautomatiseerde, audit-ready vastlegging van toegang tot gevoelige gegevens en beleidsbeslissingen.
Hoe kunnen organisaties valideren dat encryptie en toegangscontroles daadwerkelijk gevoelige analytische data beschermen?
Test continu paden die specifiek zijn voor analyses: scan query-API's op autorisatiefouten, valideer rij/kolombeveiliging bij joins, verifieer of caches geen gereguleerde velden in platte tekst opslaan en test inbeddingstokens (embed tokens) op replay-/scope-misbruik. Bevestig dit vervolgens met geautomatiseerde logging van toegang tot gevoelige velden en beleidsbeslissingen.
Wat is het verschil tussen het voorkomen van datablootstelling en het voorkomen van legitieme analytische workflows?
Het voorkomen van blootstelling draait om het standaardiseren naar veilige weergaven (aggregaties, gemaskeerde velden) en het afschermen van gevoelige drill-downs/exports; het voorkomen van workflows is een algehele blokkade die gebruikers dwingt tot omwegen (workarounds, zoals exports).
Hoe kan gedragsmatige anomaliedetectie onderscheid maken tussen een data-analist die inzichten ontdekt en een insider threat (interne dreiging) die data exfiltreert?
Stel verwacht gedrag vast per rol, en markeer vervolgens verschuivingen zoals de overgang van aggregaties naar ruwe identifiers, ongebruikelijke reikwijdtes in business-units, snelle paginering/export-loops, of nieuwe clients die query-API's aanroepen. Reageer met wrijvingsarme controles (zachte waarschuwingen, just-in-time her-authenticatie, exportlimieten).
Welke impact op latentie of queryprestaties moeten organisaties verwachten bij het toevoegen van beveiligingscontroles aan analysesystemen?
Als controles "standaard stil" zijn, blijft normaal dashboardgebruik snel (caching van aggregaties, minimale prompts), terwijl extra wrijving gereserveerd is voor acties met een hoger risico, zoals gevoelige drill-downs en exports (step-up auth, beperkte scopes, logging).
Moet de analyseverwerking plaatsvinden op speciale on-premises infrastructuur, geïsoleerd van operationele systemen?
Ja—behandel analyses als een gesegmenteerde zone: isoleer de query-engine van operationele netwerken, beperk oost-westverkeer en routeer gereguleerde data naar strenger gecontroleerde rekenpools.
Hoe conflicteren dataminimalisatiestrategieën met de behoefte aan uitgebreide analysedatasets?
Ze conflicteren wanneer minimalisatie de benodigde context verwijdert; los dit op door modellen te ontwerpen die aggregaties voorop stellen (metriek-eerst, cohorten/bereiken) en gecontroleerde drill-downs alleen toe te staan wanneer dit gerechtvaardigd en geautoriseerd is.
Welke rol zouden externe aanbieders van analyses moeten spelen in organisaties die uitsluitend on-premises data gebruiken?
Toegang door leveranciers moet de uitzondering zijn: geef de voorkeur aan ingebedde analyses binnen uw eigen grenzen; als een leverancier toch verbinding moet maken, beperk deze dan tot een gesegmenteerde zone met kortlopende inloggegevens met een beperkte scope, strikte API-scope beoordelingen/sleutelrotatie en volledige logging.
Hoe meten organisaties of hun analysebeveiliging in verhouding staat tot het daadwerkelijke bedrijfsrisico?
Stem controles af op intentie en risico (step-up alleen voor risicovolle acties), valideer echte blootstellingspunten (API's/tokens/caches/joins) en zorg voor "zichtbare verantwoordelijkheid" via automatische bewijsvastlegging in plaats van constante wrijving voor de gebruiker.
Wat is de relatie tussen de nauwkeurigheid van dataclassificatie en effectieve toegangscontrole voor analyses?
Classificatie is de basis: tag velden bij opname, neem de gevoeligheid mee in de afstamming (lineage)/joins en gebruik die tags om berekeningen te routeren en weer te geven wat elke rol mag zien. Slechte tags betekenen een falende handhaving.
Hoe kunnen organisaties datablootstelling gerelateerd aan analyses voorspellen en voorkomen voordat zich incidenten voordoen?
Combineer continue beoordeling van blootstelling (test query-API's, tokens, caches en join-gedrag) met op rollen gebaseerde anomaliedetectie en automatisch auditbewijs, zodat problemen vroegtijdig aan het licht komen zonder legitieme analyses te verstoren.