

Données sensibles en analytique métier : hébergement on-premise avec une analytique qui ne perturbe pas le flux utilisateur
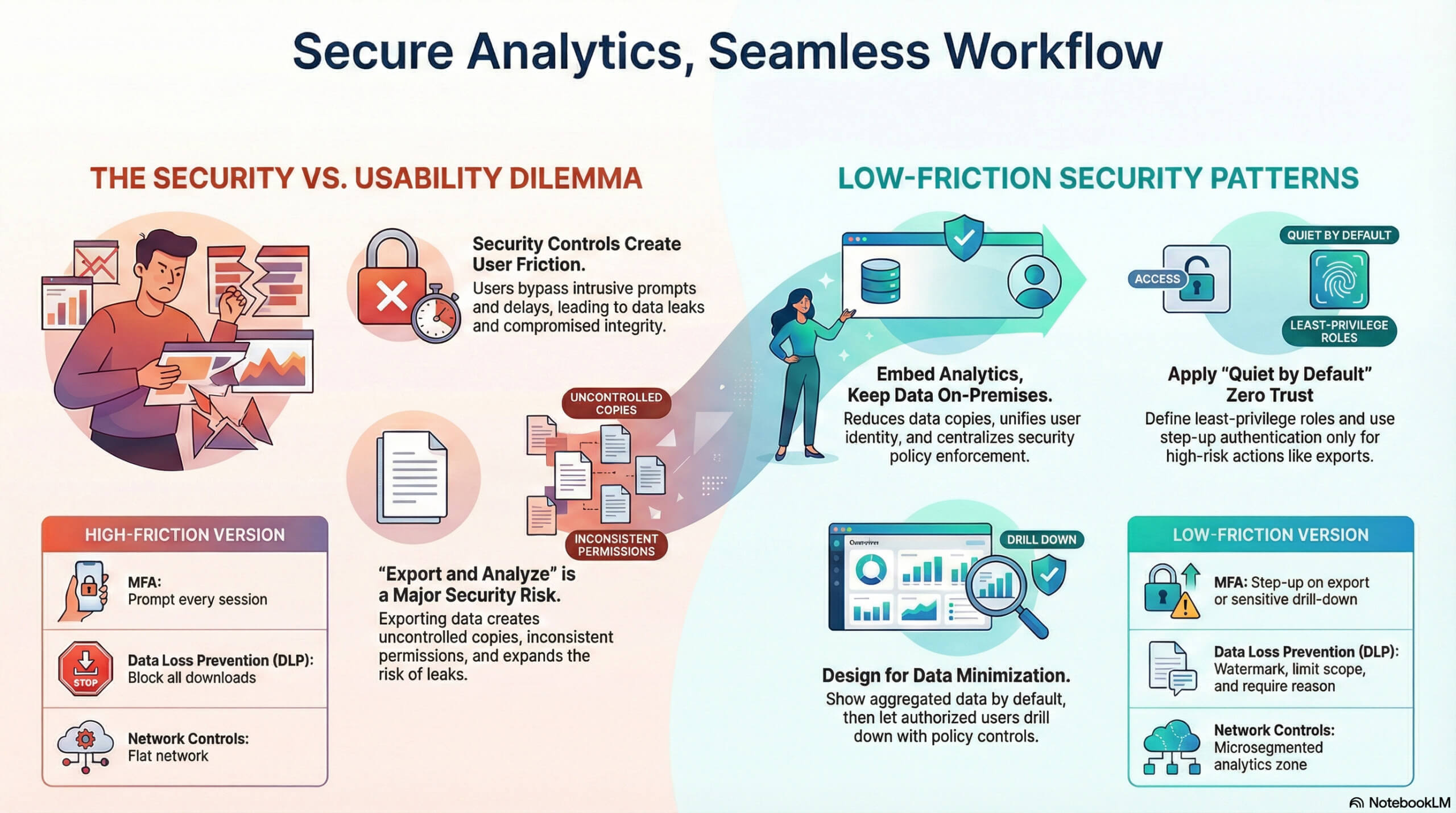
Les dirigeants semblent parfois vouloir deux choses à la fois. Des réponses rapides au sein des outils opérationnels, et un contrôle strict des données sensibles dans l'analyse d'entreprise (business analytics). Le problème, c'est la friction. De nombreux contrôles de sécurité ajoutent des invites (prompts), des retards et des écrans bloqués. Les utilisateurs les contournent ou développent une "mémoire musculaire" où ils cliquent sur un bouton sans vraiment saisir le sens du texte qu'ils voient - ou n'ont pas consciemment vu. Si vous y réfléchissez, cela vous semble-t-il familier ? Les analystes exportent vers des feuilles de calcul, c'est souvent encore leur arme de prédilection. Les dirigeants peuvent perdre confiance dans les chiffres lorsque l'histoire qu'ils racontent ne s'appuie pas également sur des faits crédibles. Pire encore si ces faits sont pollués ou compromis.
La sécurité ne consiste pas seulement à prévenir les fuites de données et à éviter qu'elles ne tombent entre de mauvaises mains ; il s'agit également de garantir l'intégrité des données fournies, les vérités sur lesquelles reposent votre histoire BI et vos analyses. Mais garantir cette certitude des données factuelles ne doit pas interférer indûment avec leur consommation et leur utilisation en rendant les méthodes de sécurité employées trop contraignantes - et c'est là toute la difficulté : l'équilibre et l'efficacité.
La solution n'est pas "moins de sécurité". C'est une sécurité qui correspond à l'intention de l'utilisateur et au risque, avec des contrôles qui restent en arrière-plan la plupart du temps. L'hébergement sur site (on-premises) aide car il maintient les jeux de données critiques, les clés d'accès et l'application des politiques à proximité des systèmes d'enregistrement (systems of record). Il réduit également l'exposition des données à des tiers et le rayon d'impact (blast radius) des fournisseurs. Lorsque l'équilibre est bon, la sécurité est endémique, efficace, omniprésente, mais pratiquement invisible.
Une question compte plus que les autres : comment les analyses peuvent-elles rester dans le flux de travail (workflow) de l'utilisateur tout en maintenant une sécurité stricte ?
Conserver les analyses dans le produit, les données sur site (On-Premises)
L'analyse intégrée (embedded) l'emporte sur "exporter et analyser"
Le flux utilisateur est interrompu lorsque les analyses se trouvent dans une destination distincte. Changer d'outil ajoute des invites de connexion, des autorisations différentes, des filtres différents et davantage d'exportations. Les exportations créent des copies, et les copies créent des fuites.
Un modèle plus sûr est l'analyse intégrée dans la même application où travaillent les utilisateurs. Cela offre trois avantages concrets pour les données sensibles dans les analyses d'entreprise :
- Moins de copies de données. Le calcul a lieu près de la source et les résultats affluent vers l'interface utilisateur (UI).
- Identité cohérente. La même identité d'utilisateur contrôle les actions et les analyses.
- Application des politiques en un seul endroit. Les règles de sécurité s'appliquent aussi bien aux transactions qu'aux requêtes.
L'hébergement sur site limite également ce qu'un fournisseur d'analyses tiers peut voir. L'accès du fournisseur devient une exception, et non la règle. C'est important car les risques liés à la chaîne d'approvisionnement et aux tiers sont un thème récurrent dans les directives cybernétiques, y compris les prédictions pour 2026 publiées par Morrison Foerster.
Objectif de conception : contrôles invisibles, responsabilité visible
Les équipes de sécurité mesurent souvent la force du contrôle qu'elles ont sur les menaces. Les utilisateurs mesurent les interruptions dans l'obtention des résultats souhaités ou les frustrations pour atteindre leurs objectifs. La bonne cible est le "silence par défaut" (quiet by default), avec des preuves solides lorsque quelque chose va mal ou a mal tourné. Il ne suffit pas d'avoir l'"intuition" que quelque chose ne va pas.
Cela correspond à l'évolution vers des contrôles de données adaptatifs et basés sur des politiques, décrits dans la discussion sur les tendances 2026 en matière de protection unifiée des données et d'automatisation de Cyberhaven.
Données sensibles dans l'analyse d'entreprise : Zero Trust sans invites constantes
Vérification continue, moindre privilège, microsegmentation
Le Zero Trust (Confiance Zéro) est adapté à l'analyse car l'accès aux requêtes est une voie à haut risque. Un seul analyste peut extraire des millions de lignes plus rapidement que n'importe quel écran d'application. En termes simples, la capacité d'accéder aux données brutes de manière exhaustive signifie une expansion des mauvaises utilisations potentielles de ces données, ainsi qu'un risque pour leur véracité si une capacité illimitée de les modifier est accordée sans le niveau de surveillance adéquat.
Appliquez le Zero Trust de manière à ne pas interrompre le flux (flow) :
- Rôles de requête à moindre privilège. Définissez les rôles par tâche, et non par titre. Séparez "afficher les cartes KPI" de "exporter les détails au niveau de la ligne".
- Microsegmentation pour les services d'analyse. Isolez le moteur de requête des réseaux opérationnels. Restreignez le trafic est-ouest.
- Renforcement (step-up) basé sur le risque uniquement lorsque nécessaire. N'ajoutez pas d'invites MFA à chaque vue de graphique. Déclenchez l'authentification renforcée lors de l'exportation, de l'élargissement des plages de sélection ou de l'accès à des champs réglementés.
Cela s'aligne sur les directives communes du Zero Trust, y compris la vérification d'identité, le moindre privilège et la segmentation décrits dans les analyses Zero Trust d'Archtis.
Modèle UX : divulgation progressive des détails sensibles
La plupart des utilisateurs n'ont pas besoin d'identifiants bruts. Donnez-leur des agrégats par défaut, puis laissez les utilisateurs autorisés explorer en détail (drill-down). L'exploration en détail devient le "point de contrôle" pour l'autorisation renforcée (step-up), la demande de commentaires de justification ou l'octroi d'un accès limité dans le temps.
Cela permet de garder les tableaux de bord rapides et réduit l'exposition sensible pendant le travail normal.
Une minimisation des données qui soutient toujours les décisions
Réduire la surface d'exposition dès la conception
La minimisation des données n'est pas un slogan. C'est une spécification de conception.
Pour les données sensibles dans les analyses d'entreprise, la minimisation ressemble à ceci :
- Modélisation axée sur les métriques (Metric-first). Précalculez les métriques métier à partir de sources sensibles, ne stockez que les valeurs dérivées dans la mesure du possible.
- Cohortes et plages par défaut. Affichez les bandes, les percentiles et les nombres, puis autorisez l'exploration en détail (drill-down) avec des contrôles.
- Rétention courte pour les résultats de requête. Mettez les agrégats en cache pour plus de vitesse, mais faites-les expirer rapidement et chiffrez les données en cache.
Cela correspond aux principes de base de la sécurité des données, tels que la limitation de la collecte et la restriction de l'accès, tels que résumés dans les meilleures pratiques de sécurité des données de Palo Alto Networks et également dans des synthèses comme l'introduction à la sécurité des données de Coursera.
Tableau : choix de minimisation qui protègent le flux
| Choix de conception | Ce que voient les utilisateurs | Gain de sécurité | Gain UX |
| Tableaux de bord axés sur les agrégats | KPI, tendances, alertes | Moins d'exposition aux données brutes | Chargement plus rapide, moins de filtres |
| Champs sensibles masqués par défaut | Identifiants partiels | Réduit les risques internes (insider risk) | Moins d'avertissements effrayants |
| Exploration en détail (Drill-down) contrôlée par politique | Détails uniquement lorsque nécessaire | Point de contrôle fort | Les invites sont rares |
| Exportations liées à un objectif | Exportation avec raison, portée | Meilleure piste d'audit (audit trail) | Intention de l'utilisateur plus claire |

Données sensibles dans l'analyse d'entreprise : Classification en temps réel et routage basé sur la sensibilité
Classifier une fois, appliquer partout
La classification échoue lorsqu'elle dépend de balises (tags) manuelles. Les pipelines d'analyse ingèrent les données de nombreux systèmes, et la sensibilité change avec les jointures (joins). La classification en temps réel et les vérifications de politiques réduisent les erreurs.
Un modèle sur site (on-prem) pratique :
- Classifiez les champs lors de l'ingestion. Étiquetez les colonnes comme publiques, internes, confidentielles, réglementées.
- Attachez des balises à la lignée (lineage). Lorsque les jeux de données se combinent, la sensibilité doit suivre.
- Acheminez selon la sensibilité. Les données réglementées restent dans des stockages à contrôle élevé et des pools de calcul à contrôle élevé.
- Affichez selon la sensibilité. L'interface utilisateur utilise les mêmes balises pour décider ce qu'un rôle peut voir.
Cela soutient la tendance vers une protection unifiée et automatisée et des boucles d'application rapides, évoquées dans les tendances 2026 de Cyberhaven.
Modèle UX : "valeurs par défaut sûres" avec des exceptions rapides
Les utilisateurs ne devraient pas choisir les niveaux de sensibilité. C'est au produit de le faire. Lorsque des exceptions sont nécessaires, utilisez un flux strict : une petite boîte de justification, une autorisation de courte durée et une journalisation (logging) visible.
Évaluation continue de l'exposition pour les surfaces d'analyse
Testez les chemins de données, pas seulement les hôtes
L'analyse, en particulier l'analyse par des tiers, crée de nouvelles surfaces d'attaque : API de requêtes, couches sémantiques, stockages de résultats en cache, points de terminaison d'exportation et jetons d'intégration (embed tokens). L'évaluation de l'exposition doit se concentrer sur ces éléments.
L'analyse intégrée offre, bien sûr, une surface d'exposition beaucoup plus petite par rapport aux solutions externes de tiers. Yellowfin met en œuvre un modèle de sécurité rigoureux pour protéger vos données d'entreprise sous plusieurs angles, y compris l'accès basé sur les rôles et le chiffrement au repos et en transit.
Étapes pratiques :
- Analysez (scannez) les API d'analyse pour détecter les autorisations défaillantes au niveau des objets.
- Testez les jetons d'intégration (embed tokens) pour détecter les abus de rejeu (replay) et de portée (scope).
- Vérifiez que les caches ne stockent pas les champs réglementés en texte clair.
- Validez la sécurité au niveau des lignes et des colonnes lors des jointures (joins).
Tableau : contrôles d'analyse courants et leur forme "à faible friction"
| Contrôle | Version à forte friction | Version à faible friction |
| MFA (Authentification multifacteur) | Invite à chaque session | Renforcement (Step-up) lors de l'exportation ou de l'exploration de détails sensibles |
| DLP (Prévention des pertes de données) | Bloquer tous les téléchargements | Filigrane, limiter la portée, journaliser, exiger un motif |
| Contrôles réseau | Réseau plat | Zone d'analyse microsegmentée |
| Journalisation (Logging) | Audits manuels | Capture automatique de preuves vers des tableaux de bord de conformité |
Chiffrement et planification post-quantique sans surprises de latence
Chiffrez les données au repos, en transit et dans le cache
Sur site (on-prem) ne signifie pas "sûr par l'emplacement". Cela signifie que vous contrôlez les clés, les réseaux et la politique. Chiffrez :
- Au repos dans les entrepôts de données (warehouses), les lakehouses et les stockages sémantiques.
- En transit pour le trafic des requêtes et les connexions d'intégration.
- Dans les caches où les équipes de performance rognent souvent sur la sécurité.
Les recommandations générales soulignent systématiquement le chiffrement et les protocoles forts comme des contrôles de base, y compris le résumé des meilleures pratiques de Palo Alto Networks.
Pour les données sensibles à longue durée de vie dans les analyses d'entreprise, commencez à planifier la préparation post-quantique. Traitez cela comme un élément de la feuille de route (roadmap) lié aux périodes de conservation des données et à la rotation des clés, et non comme une refonte soudaine. Les discussions stratégiques pour 2026 placent souvent la planification post-quantique aux côtés de programmes de protection plus larges, y compris les orientations axées sur la planification dans les stratégies de protection des données 2026 d'Hyperproof.
Une analyse comportementale qui détecte les abus sans bloquer le travail réel
Des bases de référence (baselines) par rôle, pas par utilisateur
Les analystes explorent. C'est leur travail. La détection d'anomalies doit donc comprendre les modèles de rôle.
Bons signaux :
- Passage soudain des agrégats aux identifiants bruts.
- Requêtes couvrant des unités commerciales inhabituelles.
- Pagination rapide ou boucles d'exportation.
- Nouveaux outils ou clients accédant à l'API de requête.
Ensuite, appliquez des réponses qui gardent le flux intact :
- Avertissements légers (soft warnings) intégrés au produit.
- Ré-authentification juste-à-temps (just-in-time) pour les actions sensibles.
- Limites de taux (rate limits) sur les exportations, pas sur les graphiques.
Cela correspond à la tendance de l'industrie vers des contrôles sensibles au contexte et des décisions adaptatives discutées dans plusieurs synthèses de tendances de sécurité 2026, y compris Cyberhaven et le cadre de tendance plus large du Tarian Group.
Une conformité prête pour l'audit qui ne crée pas de travail manuel
Rendez les preuves automatiques
Le travail de conformité peut souvent interrompre le flux tant pour les utilisateurs que pour les ingénieurs. La solution est la capture automatique de preuves :
- Journalisez chaque accès à un champ sensible avec l'utilisateur, le rôle, l'appareil et le but.
- Stockez les empreintes digitales (fingerprints) de la requête, et non le texte complet de la requête, au cas où le texte contiendrait des valeurs littérales.
- Enregistrez les décisions de politique, y compris les refus et les déclencheurs d'authentification renforcée (step-up).
Cela soutient "l'audit par requête" au lieu de "l'audit par feuille de calcul". L'automatisation de la conformité est un thème récurrent dans les directives de sécurité axées sur la gouvernance, y compris l'approche structurée des contrôles décrite dans Hyperproof.
Risques liés aux fournisseurs et aux tiers lorsque les données restent sur site
Traitez l'accès des fournisseurs comme un flux de travail contrôlé et journalisé
Les fournisseurs d'analyses tiers demandent souvent des extraits de données ou des connecteurs directs. Cela crée de nouvelles copies, de nouveaux identifiants et de nouvelles expositions juridiques.
Si les données sensibles dans les analyses d'entreprise doivent rester sur site (on-premises) :
- Privilégiez les analyses intégrées (embedded) qui s'exécutent dans votre périmètre.
- Si un fournisseur doit se connecter, restreignez-le à une zone réseau segmentée.
- Utilisez des identifiants à courte durée de vie et des comptes de service avec une portée limitée (scoped).
- Passez en revue les portées d'API (API scopes) et effectuez une rotation des clés selon un calendrier fixe.
Les attentes en matière de réglementation et d'infrastructures critiques pointent de plus en plus vers une gouvernance et une surveillance des fournisseurs plus strictes, comme le soulignent les prédictions 2026 en matière de cybersécurité et de confidentialité de Morrison Foerster.

Une liste de contrôle pratique pour des analyses qui restent dans le flux
Utilisez ceci comme un guide d'implémentation pour les analyses sur site servant des données sensibles :
- Placez les analyses dans l'interface utilisateur du produit opérationnel.
- Par défaut sur les agrégats, protégez les détails avec des politiques.
- Appliquez la sécurité au niveau des lignes et des colonnes dans la couche de requête.
- Classifiez les données lors de l'ingestion, conservez les balises tout au long de la lignée (lineage).
- Chiffrez le stockage, le transit et les caches. Gardez le contrôle des clés sur site.
- N'ajoutez l'authentification renforcée (step-up) que pour les actions risquées, comme l'exportation.
- Effectuez des tests d'exposition continus sur les API de requêtes et les chemins d'intégration (embed).
- Journalisez automatiquement les décisions de politique et les événements d'accès sensible.
- Traitez l'accès des fournisseurs comme rare, délimité et entièrement journalisé.
L'hébergement sur site n'est pas une question de nostalgie. C'est un choix de contrôle. Lorsqu'il est combiné à des analyses intégrées et à des modèles de sécurité à faible friction, il permet aux équipes de fournir des informations rapides sans transformer les données sensibles des analyses d'entreprise en un compromis de risque constant.
FAQ (Foire aux questions)
Comment les principes du Zero Trust s'appliquent-ils spécifiquement à l'autorisation des requêtes d'analyse sans bloquer les analyses légitimes ?
Appliquez des rôles de requête au moindre privilège par tâche, isolez la couche d'analyse/requête via la microsegmentation et utilisez le renforcement (step-up) basé sur le risque uniquement pour les actions à haut risque (exportations, portées plus larges, champs réglementés), pas pour la consultation de routine des tableaux de bord.
Quelles exigences réglementaires (RGPD, HIPAA, SOX) ont l'impact le plus direct sur la gestion des données d'analyse sur site ?
Dans la pratique, celles-ci imposent le plus directement : des contrôles d'accès stricts (niveau ligne/colonne si nécessaire), le chiffrement au repos/en transit/en cache, des vues minimisées/agrégées par défaut, des exportations contrôlées et une capture de preuves prêtes pour l'audit des accès sensibles et des décisions de politique.
Comment les organisations peuvent-elles valider que le chiffrement et les contrôles d'accès protègent réellement les données analytiques sensibles ?
Testez continuellement les voies spécifiques à l'analyse : analysez les API de requêtes pour détecter les échecs d'autorisation, validez la sécurité des lignes/colonnes lors des jointures (joins), vérifiez que les caches ne stockent pas les champs réglementés en texte clair et testez les jetons d'intégration pour détecter les abus de rejeu/portée. Corroborez ensuite avec la journalisation automatisée des accès aux champs sensibles et des décisions de politique.
Quelle est la différence entre empêcher l'exposition des données et empêcher les flux de travail analytiques légitimes ?
Prévenir l'exposition consiste à opter par défaut pour des vues sûres (agrégats, champs masqués) et à contrôler l'exploration (drill-down)/l'exportation d'informations sensibles ; empêcher les flux de travail est un blocage systématique qui oblige les utilisateurs à recourir à des solutions de contournement (comme les exportations).
Comment la détection d'anomalies comportementales peut-elle faire la distinction entre un analyste de données qui découvre des informations et une menace interne qui exfiltre des données ?
Établissez le comportement attendu par rôle, puis signalez les changements tels que le passage d'agrégats à des identifiants bruts, une portée d'unité commerciale inhabituelle, une pagination rapide/des boucles d'exportation, ou de nouveaux clients interrogeant les API. Répondez avec des contrôles à faible friction (avertissements légers, ré-authentification juste-à-temps, limites de taux d'exportation).
À quel impact sur la latence ou les performances des requêtes les organisations doivent-elles s'attendre en ajoutant des contrôles de sécurité aux systèmes d'analyse ?
Si les contrôles sont "silencieux par défaut", l'utilisation normale du tableau de bord reste rapide (mise en cache des agrégats, invites minimales), tandis que les frictions supplémentaires sont réservées aux actions à plus haut risque comme l'exploration de détails sensibles et les exportations (authentification renforcée, limites de portée, journalisation).
Le traitement des analyses doit-il avoir lieu sur une infrastructure dédiée sur site, isolée des systèmes opérationnels ?
Oui—traitez l'analyse comme une zone segmentée : isolez le moteur de requête des réseaux opérationnels, restreignez le trafic est-ouest et acheminez les données réglementées vers des pools de calcul à contrôle plus élevé.
En quoi les stratégies de minimisation des données entrent-elles en conflit avec le besoin de jeux de données d'analyse complets ?
Elles entrent en conflit lorsque la minimisation supprime le contexte nécessaire ; résolvez ce problème en concevant des modèles axés sur les agrégats (métriques en premier, cohortes/plages) et en n'autorisant l'exploration (drill-down) contrôlée que lorsqu'elle est justifiée et autorisée.
Quel rôle les fournisseurs d'analyses tiers devraient-ils jouer dans les organisations utilisant uniquement des données sur site ?
L'accès du fournisseur doit être l'exception : privilégiez l'analyse intégrée (embedded) à l'intérieur de votre périmètre ; si un fournisseur doit se connecter, limitez-le à une zone segmentée avec des identifiants à courte durée de vie et à portée limitée, un examen strict de la portée des API / rotation des clés et une journalisation complète.
Comment les organisations mesurent-elles si la sécurité de leurs analyses est proportionnelle au risque commercial réel ?
Alignez les contrôles sur l'intention et le risque (renforcement uniquement pour les actions risquées), validez les points d'exposition réels (API/jetons/caches/jointures) et garantissez une "responsabilité visible" via la capture automatique de preuves plutôt qu'une friction constante pour l'utilisateur.
Quelle est la relation entre l'exactitude de la classification des données et l'efficacité du contrôle d'accès aux analyses ?
La classification est la base : étiquetez les champs lors de l'ingestion, transmettez la sensibilité tout au long de la lignée/des jointures, et utilisez ces balises pour acheminer les calculs et afficher ce que chaque rôle peut voir. De mauvaises balises signifient une application défaillante.
Comment les organisations peuvent-elles prévoir et prévenir l'exposition des données liée aux analyses avant que des incidents ne se produisent ?
Combinez l'évaluation continue de l'exposition (testez les API de requête, les jetons, les caches et le comportement des jointures) avec la détection d'anomalies basée sur les rôles et les preuves d'audit automatiques, afin que les problèmes soient signalés tôt sans perturber l'analyse légitime.