
Overzicht architectuur
-
In this section
Updated 3 juni 2020 -
Overzicht architectuur
Wat zijn de belangrijkste onderdelen van Yellowfin Architecture
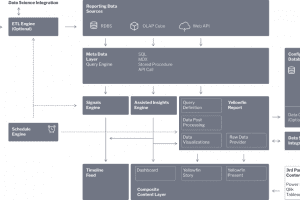
Hieronder volgt een beschrijving van de belangrijkste functionele componenten van de Yellowfin architectuur.
Configuration Database – slaat alle configuratiegegevens op die nodig zijn voor Yellowfin, inclusief informatie over gebruikers, beveiliging, gegevensbronnen en inhoud die is gemaakt in Yellowfin. De gecreëerde inhoud omvat definities van rapporten, grafieken, dashboards, presentaties en verhalen. Kan worden geïmplementeerd in verschillende relationele databases, waaronder SQLServer, MySQL en Oracle.
Reporting Data Sources – Yellowfin verbindt live met een breed scala van gegevensbronnen, waaronder de meeste populaire relationele en niet-relationele databases (met een geschikte jdbc driver), kubussen (via MDX), platte bestanden en API-eindpunten (met inbegrip van out of the box aansluitingen op populaire cloud-toepassingen). Dit framework is uitbreidbaar en klanten kunnen hun eigen verbindingen maken of een verbinding van een derde partij gebruiken als die beschikbaar is.
ETL Engine (optioneel) – dit is een optioneel onderdeel dat klanten kunnen gebruiken als ze hun gegevens verder moeten transformeren naar een vorm die geschikt is voor analyse. Gegevens kunnen van elke bron worden gelezen, gecombineerd, getransformeerd en vervolgens teruggeschreven naar elk beschrijfbaar DBMS dat wij ondersteunen. Er is een grote verscheidenheid aan transformatiestappen beschikbaar, waaronder het samenvoegen van gegevens, het splitsen van gegevens, het maken van nieuwe kolommen, het wijzigen van gegevenstypes, het vervangen van waarden enzovoort. Daarnaast kunnen klanten een ETL workflow koppelen aan een Data Science model van een derde partij om gegevens te verrijken met de resultaten van een voorspellend algoritme. We ondersteunen momenteel modellen die geëxporteerd worden in pmml-formaat, evenals live verbindingen met R Servers, H20.ai en AWS SageMaker. Het ETL-stappenraamwerk is uitbreidbaar en klanten kunnen hun eigen aangepaste ETL-stappen bouwen en toevoegen.
Meta-datalaag – deze laag bevat alle noodzakelijke informatie over de gegevens waaruit rapporten moeten worden opgebouwd. Dit omvat de tabelstructuren, join-condities, berekende velden, gegevensopmaak enzovoort. Deze gegevens worden vervolgens gebruikt door de Query Engine die DB-specifieke query’s genereert in de vorm van SQL, MDX of andere aanroepen om dynamisch query’s uit te voeren op de live gegevensverbinding. Gegevens kunnen ook afkomstig zijn van een Stored Procedure of handgecodeerde SQL. Op dit niveau worden beveiligingsaspecten toegepast, waaronder de toepassing van toegangsfilters en/of vervanging van gegevensbronnen om logische of fysieke scheiding van gegevens in een multi-tenant omgeving te ondersteunen.
Yellowfin Report – deze module is verantwoordelijk voor het opvragen van gegevens bij de Query Engine, het verbeteren van die gegevens waar nodig en het genereren van de gevraagde visualisaties. Query Definitions bevatten de nodige details over welke gegevens precies nodig zijn om elk rapport of visualisatie te produceren. Er zijn verschillende sub-engines die extra bewerkingen uitvoeren op de gegevens zodra deze zijn teruggestuurd van de query engine:
- Post-processing Engine – deze engine neemt de ruwe gegevens van een query en bereidt ze voor op presentatie. Dit omvat het combineren van gegevens uit verschillende gegevensbronnen, het uitvoeren van kruistabellen van gegevens, het converteren van gegevenstypen, het formatteren van gegevens en ook het verrijken van gegevens door het uitvoeren van complexe post-processing. Post-processing kan het uitvoeren van geavanceerde statistische berekeningen omvatten (zoals percentage van het totaal, StdDev, voorspellingen enz.) en het aanroepen van toepassingen van derden om gegevens te verrijken (zoals het aanroepen van een voorspellend gegevenswetenschappelijk model dat hetzelfde framework gebruikt als de ETL engine). Functies voor nabewerking zijn uitbreidbaar en klanten kunnen hun eigen functies schrijven en opnemen om specifieke bewerkingen uit te voeren voordat de gegevens worden weergegeven.
- Visualization Engine – deze engine genereert de zichtbare inhoud voor gebruikers, waaronder rapporten, grafieken, dashboards, presentaties en verhalen. Dit framework is ook uitbreidbaar, er kunnen bijvoorbeeld Javascript-grafieken worden toegevoegd, evenals andere op maat gemaakte UI-componenten.
- Raw Data Provider – de data sets geretourneerd van rapporten zijn toegankelijk via API-aanroepen. Klanten kunnen aangepaste verwerking uitvoeren op de onderliggende datasets voordat de gegevens worden gepresenteerd in een Yellowfin-visualisatie of een aangepast UI-element ontwikkeld door de klant.
- Data Cache – Yellowfin kan worden geconfigureerd om data te cachen om de eindgebruiker ervaring te versnellen. Een verscheidenheid aan gegevens kan worden gecached, waaronder actuele rapportgegevens, filterwaarden, favorieten enzovoort. Het verversen van gegevens kan worden gepland via de Yellowfin scheduler.
Inhoud Laag – Inhoud kan worden geconsumeerd via de Yellowfin applicatie van de meeste populaire browsers, van de native Yellowfin mobiele App (IOS of Android) en individuele componenten kunnen worden ingesloten in toepassingen via API-oproepen. Gebruikers zullen meestal interactie hebben met Yellowfin visualisaties via een Dashboard, Presentatie of Story – of een visualisatie die direct is ingebed in een applicatie van derden. De contentlaag kan worden aangepast aan de behoeften van de klant. Andere mogelijkheden zijn beschikbaar op de inhoudslaag, waaronder:-
- Inhoud van derden – vanaf het Story-product kunnen klanten visualisaties van BI-apps van derden integreren in Yellowfin. Inhoud van Tableau, Qlik en PowerBI kan worden geïntegreerd en bekeken naast de inhoud van Yellowfin.
- Tijdlijnfeed – de tijdlijnfeed biedt gebruikers gepersonaliseerde waarschuwingen en relevante inhoud via de Yellowfin-applicatie, de mobiele app of via een REST API.
Scheduling Engine – bevat een flexibele scheduling engine om ETL jobs, Report distribution, Signals jobs en andere systeemtaken te plannen. Sommige geplande taken kunnen worden getriggerd op basis van bijvoorbeeld het overschrijden van vooraf gedefinieerde drempels.
Signalenengine – de Signalenengine analyseert gegevens automatisch om data-events van betekenis te identificeren en genereert vervolgens gepersonaliseerde waarschuwingen die worden afgeleverd via de Timeline Feed, in de browserclient of mobiele client. Signals-taken worden geconfigureerd in en maken gebruik van de meta-datalaag en kunnen worden gepland om met elke frequentie te worden uitgevoerd met behulp van de Scheduling-engine. De Signals engine is complex en bevat een engine voor het genereren van tijdreeksen, meerdere algoritmen voor het detecteren van gebeurtenissen, een engine voor rangschikking en personalisatie en een engine voor meldingen.
Assisted Insights Engine – dit is een reeks algoritmes die worden aangeroepen om automatisch en on-the-fly gegevensinzichten te genereren. Deze inzichten zijn toegankelijk via directe gebruikersinteractie met een grafiekvisualisatie, via het proces van de rapportbouwer en ook om diepere verklaringen achter Signalen te geven.
-
Technische architectuur
Wat zijn de belangrijkste onderdelen van de architectuur van het Yellowfin-platform?
Yellowfin bestaat uit een Java Application Server (die draait op Apache Tomcat) en een Repository Database. De Repository Database kan bestaan uit een van de volgende ondersteunde databasesystemen: PostgreSQL, Microsoft SQL Server, MySQL, Oracle, DB2 of Ingres.
De applicatie kan worden geschaald voor grotere capaciteit en failover door meerdere Yellowfin Application Servers te clusteren tegen dezelfde database.
Toepassingsserver
Welke applicatieserver kan ik gebruiken om Yellowfin te draaien?
Yellowfin installeert een instantie van Tomcat tijdens de installatie. Klanten die een Java Application Server van derden willen gebruiken, kunnen Yellowfin consumeren als een WAR-bestand, voor implementatie op hun bestaande infrastructuur.
Tomcat heeft verschillende connectoren die integratie met externe webservers mogelijk maken, zodat Yellowfin kan worden blootgesteld aan een bestaande website of portal. Dit omvat Apache, IIS en Nginx.
Worden er externe componenten of bibliotheken meegeleverd met Yellowfin?
Er worden geen propriëtaire bibliotheken meegeleverd met Yellowfin.
Welke open source bibliotheken worden met Yellowfin meegeleverd?
Yellowfin wordt geleverd met veel open-source bibliotheken met toegestane licenties. Een volledige lijst hiervan is gedocumenteerd in de legal directory van de Yellowfin installatie.
Komen mijn rapportagegegevens ooit tot rust in Yellowfin?
Yellowfin slaat gegevens tijdelijk op in het geheugen terwijl rapporten en dashboards worden bekeken. Andere opties, die niet standaard zijn ingeschakeld, maken het mogelijk om rapporten en filterwaarden in de cache op te slaan in de Repository Database. Dit wordt gebruikt voor het maken van een momentopname van een rapport en om gebruikers filterwaarden te laten kiezen uit een vervolgkeuzelijst. De rapportgegevenscache kan ook gegevens in het geheugen opslaan. Hiermee wordt de dataset van een rapportquery opgeslagen voor hergebruik binnen een instelbare periode.
Repository Databank
Waar worden mijn configuratiegegevens opgeslagen?
Alle configuratiegegevens en meta-gegevens, inclusief gebruikers, groepen en inhoudsdefinities worden opgeslagen in de Repository Database in een relationeel schema. Deze database wordt bij de installatie aangemaakt en kan bestaan uit een van de volgende ondersteunde databasesystemen: PostgreSQL, Microsoft SQL Server, MySQL, Oracle, DB2 of Ingres.
Hoe maak ik een back-up van mijn configuratiegegevens?
Een volledige back-up van de configuratie van Yellowfin kan worden gemaakt door een back-up te maken van de database van het archief. Back-ups kunnen worden gebruikt voor periodieke snapshots, of voor het verplaatsen of klonen van omgevingen tussen systemen. Door gebruik te maken van databasefunctionaliteit, zoals Log Shipping, of clustering kunnen configuratiegegevens in realtime worden geback-upt, en failover en disaster recovery bieden.
-
Openheid en uitbreidbaarheid
Overal inzetten
Op welke besturingssystemen kan ik implementeren?
Yellowfin kan worden geïnstalleerd op Windows, Linux of Mac OSX gebaseerde desktop of laptop voor evaluatie- of trainingsdoeleinden en geïnstalleerd op Windows, Linux of Mac OSX gebaseerde servers voor evaluatie-, trainings- en productiedoeleinden.
In welke cloudomgevingen kan ik implementeren?
Yellowfin werkt met alle grote cloudproviders, waaronder AWS, Azure, GCP en meer.
Kan ik Yellowfin-instanties on premise draaien?
Ja, je kunt on-premise of in de cloud implementeren.
Geen leveranciersvergrendeling
Kan ik voorkomen dat ik vastzit aan het Yellowfin-platform?
ESCROW – verleent u toegang tot de broncode van het platform in geval van insolventie van Yellowfin
Toegang tot uw content design en code extensies (die u bezit) – zelfs als u stopt met het gebruik van Yellowfin, kunt u gebruik maken van de rijke visuele inhoud en code extensies van uw apps en dashboards naar re-engineering in een ander platform of technologie
Uw gegevens kunnen worden opgeslagen in een database van uw keuze – deze is te allen tijde uw eigendom en toegankelijkZit ik vast aan een eigen database?
Nee, Yellowfin heeft geen eigen database of in-memory database. Alle gegevens worden opgeslagen in algemeen gebruikte database management systemen van uw keuze.
Als gevolg hiervan hebt u altijd toegang tot uw gegevens en kunt u deze gebruiken met andere tools, of uw gegevens verplaatsen naar een ander DBMS van uw keuze.Moet ik een eigen scripttaal leren?
Nee, Yellowfin heeft geen eigen scripting talen om gegevens te verplaatsen of visualisaties te bouwen, gebruikt. Yellowfin maakt alleen gebruik van gemeenschappelijke industriële talen of drag and drop functionaliteit voor al haar processen. Bijvoorbeeld, om een Yellowfin metadata laag te creëren kunt u gebruik maken van drag and drop GUI of SQL, of voor Code-modus op dashboards gebruik maken van HTML, JavaScript en CSS.
Kan ik Yellowfin in elke omgeving hosten?
Met Yellowfin kun je on premise implementeren, in je eigen datacenter of op de cloudprovider van je keuze, zoals AWS, Azure, Google, Oracle enz.
Kan ik mijn bestaande datawarehouseomgeving gebruiken?
Ja, Yellowfin maakt verbinding met veel DBMS en neemt geen gegevens op in een eigen formaat. Dus als je gegevens al zijn voorbereid en in een formaat dat is geoptimaliseerd voor rapportage, hoef je ze niet te verplaatsen of verder aan je gegevens te werken. Maak gewoon verbinding met uw datawarehouse en begin met het bouwen van inhoud.
Blootgestelde API's
Wat voor API’s biedt Yellowfin?
Yellowfin heeft twee belangrijke API-mogelijkheden:
De JavaScript API – gebruikt voor het insluiten van rapport- en dashboardinhoud in een toepassing van derden
Web Services API – een rijke verscheidenheid aan diensten die worden gebruikt voor het automatiseren van administratieve taken, het programmatisch manipuleren van inhoud zoals gebruikers, beveiligingsmachtigingen van meta-gegevens, of voor het integreren van inhoud in een toepassing (webtoepassing of mobiele app). Zowel SOAP als REST webservices worden ondersteund.Kan ik Yellowfin-processen automatiseren?
Ja, allerlei administratieve processen kunnen worden geautomatiseerd met behulp van de webserviceslaag.
Kan ik in Yellowfin automatisch datamodellen maken op basis van mijn schema?
Ja – het meta-datamodel kan direct worden gemanipuleerd met behulp van webservices, of inhoudsbestanden kunnen extern worden gebouwd volgens de overeengekomen standaard en geïmporteerd in Yellowfin met behulp van de Import webservice.
Uitbreidbaarheid
Hoe kan ik de functionaliteit van Yellowfin uitbreiden?
Yellowfin biedt verschillende manieren om onze functionaliteit uit te breiden. Je kunt aangepaste workflows en gebruikerservaringen maken, uitbreidingen toevoegen via onze plug-in componenten en nog veel meer. Voor een volledig overzicht van wat er mogelijk is , zie Yellowfin uitbreiden