
Yellowfin Evaluation Guide
Yellowfin is used for both enterprise analytics and embedded analytics use cases and for building bespoke analytical applications. Use this guide to ensure Yellowfin is the right technical fit for your requirements.

Überblick über die Architektur
-
In this section
Updated 3 Juni 2020 -
Überblick über die Architektur
Was sind die Schlüsselkomponenten der Yellowfin-Architektur?
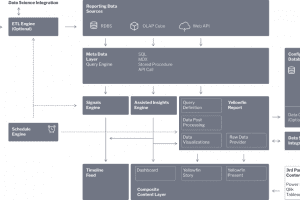
Im Folgenden finden Sie eine Beschreibung der wichtigsten funktionalen Komponenten der Yellowfin-Architektur.
Konfigurationsdatenbank – speichert alle von Yellowfin benötigten Konfigurationsdaten, einschließlich Informationen über Benutzer, Sicherheit, Datenquellen und in Yellowfin erstellte Inhalte. Zu den erstellten Inhalten gehören Definitionen von Berichten, Diagrammen, Dashboards, Präsentationen und Stories. Kann in einer Vielzahl von relationalen Datenbanken wie SQLServer, MySQL und Oracle implementiert werden.
Reporting-Datenquellen – Yellowfin stellt eine Live-Verbindung zu einer Vielzahl von Datenquellen her, darunter die meisten gängigen relationalen und nicht-relationalen Datenbanken (mit einem geeigneten JDBC-Treiber), Cubes (über MDX), Flat Files und API-Endpunkte (einschließlich Standardkonnektoren zu gängigen Cloud-Anwendungen). Dieses Framework ist erweiterbar, und Kunden können ihre eigenen Verbindungen erstellen oder eine Verbindung eines Drittanbieters verwenden, wenn eine solche verfügbar ist.
ETL-Engine (optional) – dies ist eine optionale Komponente, die Kunden nutzen können, wenn sie ihre Daten weiter in eine für Analysen geeignete Form umwandeln müssen. Die Daten können aus jeder beliebigen Quelle gelesen, kombiniert und umgewandelt werden und werden dann in jedes von uns unterstützte beschreibbare DBMS zurückgeschrieben. Es steht eine Vielzahl von Transformationsschritten zur Verfügung, darunter das Zusammenführen von Daten, das Aufteilen von Daten, das Erstellen neuer Spalten, das Ändern von Datentypen, das Ersetzen von Werten und so weiter. Darüber hinaus können Kunden einen ETL-Workflow mit einem Data Science-Modell eines Drittanbieters verbinden, um Daten mit den Ergebnissen eines Vorhersagealgorithmus anzureichern. Wir unterstützen derzeit Modelle, die im pmml-Format exportiert werden, sowie Live-Verbindungen zu R-Servern, H20.ai und AWS SageMaker. Das ETL-Schritt-Framework ist erweiterbar und Kunden können ihre eigenen benutzerdefinierten ETL-Schritte erstellen und einfügen.
Metadatenebene – diese Ebene enthält alle notwendigen Informationen über die Daten, aus denen Berichte erstellt werden sollen. Dazu gehören die Tabellenstrukturen, Verknüpfungsbedingungen, berechnete Felder, Datenformatierung usw. Diese Daten werden dann von der Query Engine verwendet, die DB-spezifische Abfragen in Form von SQL, MDX oder anderen Aufrufen zur dynamischen Abfrage der Live-Datenverbindung generiert. Die Daten können auch über eine Stored Procedure oder handcodiertes SQL bezogen werden. Auf dieser Ebene werden Sicherheitsaspekte angewendet, einschließlich der Anwendung von Zugriffsfiltern und/oder der Ersetzung von Datenquellen, um die logische oder physische Trennung von Daten in einer mandantenfähigen Umgebung zu unterstützen.
Yellowfin Report – dieses Modul ist dafür verantwortlich, Daten von der Query Engine anzufordern, diese Daten bei Bedarf zu erweitern und die gewünschten Visualisierungen zu erstellen. Abfragedefinitionen enthalten die notwendigen Details darüber, welche Daten genau für die Erstellung eines Berichts oder einer Visualisierung benötigt werden. Es gibt verschiedene Sub-Engines, die zusätzliche Verarbeitungen an den Daten vornehmen, sobald diese von der Query Engine zurückgegeben werden:
- Nachbearbeitungs-Engine – diese Engine nimmt die Rohdaten aus einer Abfrage und bereitet sie für die Präsentation auf. Dazu gehört das Kombinieren von Daten aus unterschiedlichen Datenquellen, das Durchführen von Kreuztabellierungen, das Konvertieren von Datentypen, das Formatieren von Daten und auch das Anreichern von Daten durch komplexe Nachbearbeitung. Die Nachbearbeitung kann die Ausführung fortgeschrittener statistischer Berechnungen (wie z.B. prozentualer Anteil an der Gesamtzahl, StdDev, Prognosen usw.) und den Aufruf von Drittanbieteranwendungen zur Anreicherung von Daten (wie z.B. den Aufruf eines prädiktiven datenwissenschaftlichen Modells unter Verwendung desselben Frameworks wie die ETL-Engine) umfassen. Die Nachbearbeitungsfunktionen sind erweiterbar, und die Kunden können ihre eigenen Funktionen schreiben und einbinden, um bestimmte Verarbeitungen vor der Anzeige der Daten durchzuführen.
- Visualisierungs-Engine – diese Engine generiert die sichtbaren Inhalte für die Benutzer, darunter Berichte, Diagramme, Dashboards, Präsentationen und Stories. Dieses Framework ist außerdem erweiterbar. So können beispielsweise Javascript-Diagramme und andere benutzerdefinierte UI-Komponenten integriert werden.
- Rohdatenanbieter – die von Berichten zurückgegebenen Datensätze sind über API-Aufrufe zugänglich. Kunden können die zugrunde liegenden Datensätze vor der Darstellung der Daten in einer Yellowfin-Visualisierung oder einem vom Kunden entwickelten benutzerdefinierten UI-Element individuell verarbeiten.
- Daten-Cache – Yellowfin kann so konfiguriert werden, dass Daten zwischengespeichert werden, um die Benutzerfreundlichkeit zu erhöhen. Eine Vielzahl von Daten kann zwischengespeichert werden, darunter aktuelle Berichtsdaten, Filterwerte, Favoriten usw. Die Aktualisierung der Daten kann über den Yellowfin Scheduler geplant werden.
Inhaltsebene – Inhalte können über die Yellowfin-Anwendung von den meisten gängigen Browsern aus konsumiert werden, von der nativen mobilen Yellowfin-App (IOS oder Android) aus und einzelne Komponenten können über API-Aufrufe in Anwendungen eingebettet werden. Benutzer interagieren mit Yellowfin-Visualisierungen in der Regel über ein Dashboard, eine Präsentation oder eine Story – oder eine direkt in eine Anwendung eines Drittanbieters eingebettete Visualisierung. Die Inhaltsebene kann umgestaltet und an die Bedürfnisse des Kunden angepasst werden. Auf der Inhaltsebene sind weitere Funktionen verfügbar, darunter
- Inhalte von Drittanbietern – beginnend mit dem Produkt Story können Kunden Visualisierungen aus BI-Anwendungen von Drittanbietern in Yellowfin einbetten. Inhalte von Tableau, Qlik und PowerBI können integriert und zusammen mit Inhalten von Yellowfin angezeigt werden.
- Timeline Feed – der Timeline Feed liefert Nutzern personalisierte Benachrichtigungen und relevante Inhalte über die Yellowfin-Anwendung, die mobile App oder über eine REST API.
Scheduling Engine – enthält eine flexible Scheduling Engine zur Planung von ETL-Aufträgen, Berichtsverteilung, Signalaufträgen und anderen Systemaufgaben. Einige geplante Aufgaben können ausgelöst werden, z.B. wenn vordefinierte Schwellenwerte überschritten werden.
Signal-Engine – die Signal-Engine analysiert automatisch Daten, um wichtige Datenereignisse zu identifizieren, und generiert dann personalisierte Warnmeldungen, die über den Timeline-Feed entweder im Browser-Client oder im mobilen Client ausgegeben werden. Signals-Jobs werden in der Metadaten-Ebene konfiguriert und können mit Hilfe der Scheduling-Engine in beliebigen Abständen ausgeführt werden. Die Signals-Engine ist komplex und enthält eine Engine zur Erzeugung von Zeitserien, mehrere Algorithmen zur Erkennung von Ereignissen, eine Ranking- und Personalisierungs-Engine sowie eine Benachrichtigungs-Engine.
Assisted Insights Engine – dies ist eine Reihe von Algorithmen, die aufgerufen werden, um automatisch Dateneinblicke on the fly zu generieren. Diese Einblicke sind durch direkte Benutzerinteraktion mit einer Diagrammvisualisierung, durch den Berichtserstellungsprozess und auch zur Bereitstellung tieferer Erklärungen hinter den Signalen zugänglich.
-
Technische Architektur
Was sind die wichtigsten Komponenten der Yellowfin-Plattformarchitektur?
Yellowfin besteht aus einem Java-Anwendungsserver (der auf Apache Tomcat läuft) und einer Repository-Datenbank. Die Repository-Datenbank kann auf einem der folgenden unterstützten Datenbanksysteme bestehen: PostgreSQL, Microsoft SQL Server, MySQL, Oracle, DB2 oder Ingres.
Die Anwendung kann für eine größere Kapazität und Ausfallsicherheit skaliert werden, indem mehrere Yellowfin Application Server für dieselbe Repository-Datenbank geclustert werden.
Anwendungsserver
Welchen Anwendungsserver kann ich verwenden, um Yellowfin auszuführen?
Yellowfin installiert während der Installation eine Instanz von Tomcat. Kunden, die einen Java-Anwendungsserver eines Drittanbieters verwenden möchten, können Yellowfin als WAR-Datei konsumieren, um es in ihrer bestehenden Infrastruktur einzusetzen.
Tomcat verfügt über mehrere Konnektoren, die die Integration mit externen Webservern ermöglichen, damit Yellowfin auf einer bestehenden Website oder einem Portal eingesetzt werden kann. Dazu gehören Apache, IIS und Nginx.
Werden mit Yellowfin externe proprietäre Komponenten oder Bibliotheken mitgeliefert?
Mit Yellowfin werden keine proprietären Bibliotheken ausgeliefert.
Welche Open-Source-Bibliotheken werden mit Yellowfin ausgeliefert?
Yellowfin wird mit vielen Open-Source-Bibliotheken ausgeliefert, die unter einer zulässigen Lizenz stehen. Eine vollständige Liste dieser Bibliotheken finden Sie im rechtlichen Verzeichnis der Yellowfin-Installation.
Werden meine Berichtsdaten jemals in Yellowfin gespeichert?
Yellowfin speichert die Daten vorübergehend im Speicher, während die Berichte und Dashboards angezeigt werden. Andere Optionen, die nicht standardmäßig aktiviert sind, ermöglichen das Zwischenspeichern von Berichten und Filterwerten in der Repository-Datenbank. Dies wird verwendet, um einen Schnappschuss eines Berichts zu erstellen und um Benutzern die Möglichkeit zu geben, Filterwerte aus einer Dropdown-Liste auszuwählen. Der Berichtsdaten-Cache kann auch Daten im Speicher ablegen. Dadurch wird der Datensatz einer Berichtsabfrage für die Wiederverwendung innerhalb eines konfigurierbaren Zeitraums gespeichert.
Repository-Datenbank
Wo werden meine Konfigurationsdaten gespeichert?
Alle Konfigurationsdaten und Metadaten, einschließlich Benutzer, Gruppen und Inhaltsdefinitionen, werden in der Repository-Datenbank in einem relationalen Schema gespeichert. Diese Datenbank wird bei der Installation erstellt und kann in einem der folgenden unterstützten Datenbanksysteme vorhanden sein: PostgreSQL, Microsoft SQL Server, MySQL, Oracle, DB2 oder Ingres.
Wie kann ich meine Konfigurationsdaten sichern?
Ein vollständiges Backup der Yellowfin-Konfiguration kann durch eine Sicherung der Repository-Datenbank erstellt werden. Backups können für regelmäßige Snapshots oder für das Verschieben oder Klonen von Umgebungen zwischen Systemen verwendet werden. Die Verwendung von Datenbankfunktionen wie Log Shipping oder Clustering ermöglicht die Sicherung von Konfigurationsdaten in Echtzeit und bietet Failover und Disaster Recovery.
-
Offenheit & Erweiterbarkeit
Überall einsatzbereit
Für welche Betriebssysteme kann ich eine Implementierung durchführen?
Yellowfin kann auf Windows-, Linux- oder Mac OSX-basierten Desktops oder Laptops zu Evaluierungs- oder Schulungszwecken und auf Windows-, Linux- oder Mac OSX-basierten Servern zu Evaluierungs-, Schulungs- und Produktionszwecken installiert werden.
In welchen Cloud-Umgebungen kann ich bereitstellen?
Yellowfin arbeitet mit allen großen Cloud-Anbietern wie AWS, Azure, GCP und anderen zusammen.
Kann ich Yellowfin-Instanzen vor Ort betreiben?
Ja, Sie können es vor Ort oder in der Cloud einsetzen.
Kein Vendor Lock-in
Kann ich vermeiden, an die Yellowfin-Plattform gebunden zu sein?
ESCROW – gewährt Ihnen Zugriff auf den Quellcode der Plattform im Falle einer Insolvenz von Yellowfin
Zugriff auf Ihr Inhaltsdesign und Ihre Code-Erweiterungen (die Ihnen gehören) – selbst wenn Sie Yellowfin nicht mehr nutzen, können Sie die reichhaltigen visuellen Inhalte und Code-Erweiterungen Ihrer Anwendungen und Dashboards für die Umgestaltung in einer anderen Plattform oder Technologie verwenden.
Ihre Daten können in einer beliebigen Datenbank Ihrer Wahl gespeichert werden – diese gehört Ihnen und ist jederzeit zugänglich.Werde ich an eine proprietäre Datenbank gebunden sein?
Nein, Yellowfin hat keine eigene proprietäre Datenbank oder In-Memory-Datenbank. Alle Daten werden in gängigen Datenbankmanagementsystemen Ihrer Wahl gespeichert.
Sie können also jederzeit auf Ihre Daten zugreifen und sie mit anderen Tools verwenden oder Ihre Daten in ein anderes DBMS Ihrer Wahl verschieben.Muss ich eine proprietäre Skriptsprache lernen?
Nein, Yellowfin verwendet keine proprietären Skriptsprachen, um Daten zu verschieben oder Visualisierungen zu erstellen. Yellowfin verwendet nur branchenübliche Sprachen oder Drag-and-Drop-Funktionen für alle seine Prozesse. Um beispielsweise eine Yellowfin-Metadatenebene zu erstellen, können Sie eine Drag-and-Drop-GUI oder SQL verwenden, oder für den Code-Modus auf Dashboards HTML, JavaScript und CSS.
Kann ich Yellowfin in jeder beliebigen Umgebung hosten lassen?
Mit Yellowfin können Sie vor Ort, in Ihrem eigenen Rechenzentrum oder bei einem Cloud-Anbieter Ihrer Wahl wie AWS, Azure, Google, Oracle usw. bereitstellen.
Kann ich meine bestehende Data Warehouse-Umgebung verwenden?
Ja, Yellowfin kann mit vielen DBMS verbunden werden und nimmt die Daten nicht in ein proprietäres Format auf. Wenn Ihre Daten also bereits aufbereitet sind und in einem Format vorliegen, das für die Berichterstattung optimiert ist, müssen Sie sie nicht verschieben oder weiter bearbeiten. Stellen Sie einfach eine Verbindung zu Ihrem Data Warehouse her und beginnen Sie mit der Erstellung von Inhalten.
Offengelegte API's
Welche Arten von APIs stellt Yellowfin zur Verfügung?
Yellowfin verfügt über zwei Haupt-API-Funktionen:
Die JavaScript-API – zum Einbetten von Berichts- und Dashboard-Inhalten in eine Anwendung eines Drittanbieters
Web Services API – eine Vielzahl von Diensten zur Automatisierung von Verwaltungsaufgaben, zur programmatischen Bearbeitung von Inhalten wie Benutzern, Sicherheitsberechtigungen von Metadaten oder zur Integration von Inhalten in eine Anwendung (Webanwendung oder mobile App). Es werden sowohl SOAP- als auch REST-Webdienste unterstützt.Kann ich die Yellowfin-Prozesse automatisieren?
Ja, eine Vielzahl von Verwaltungsprozessen kann mit Hilfe der Web Services-Schicht automatisiert werden.
Kann ich Datenmodelle in Yellowfin automatisch auf der Grundlage meines Schemas erstellen?
Ja – das Metadatenmodell kann mit Hilfe von Webdiensten direkt bearbeitet werden, oder Inhaltsdateien können extern nach dem vereinbarten Standard erstellt und mit dem Webdienst Import in Yellowfin importiert werden.
Erweiterbarkeit
Wie kann ich die Funktionalität von Yellowfin erweitern?
Yellowfin bietet eine Vielzahl von Möglichkeiten, unsere Funktionalität zu erweitern. Sie können benutzerdefinierte Workflows und Benutzererfahrungen erstellen, Erweiterungen durch unsere Plug-in-Komponenten hinzufügen und vieles mehr. Eine vollständige Übersicht über die Möglichkeiten finden Sie unter Yellowfin erweitern