
Yellowfin Evaluation Guide
Yellowfin is used for both enterprise analytics and embedded analytics use cases and for building bespoke analytical applications. Use this guide to ensure Yellowfin is the right technical fit for your requirements.

Panoramica dell’architettura
-
In this section
Updated 3 Giugno 2020 -
Panoramica dell'architettura
Quali sono i componenti chiave dell’Architettura Yellowfin
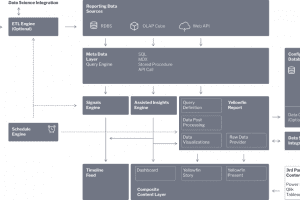
Di seguito sono descritti i principali componenti funzionali dell’architettura di Yellowfin.
Database di configurazione – memorizza tutti i dati di configurazione richiesti da Yellowfin, comprese le informazioni su utenti, sicurezza, fonti di dati e contenuti creati in Yellowfin. I contenuti creati includono le definizioni di report, grafici, dashboard, presentazioni e storie. Può essere implementato in una varietà di database relazionali, tra cui SQLServer, MySQL e Oracle.
Fonti di dati per il reporting – Yellowfin si connette in tempo reale a un’ampia varietà di fonti di dati, tra cui i più diffusi database relazionali e non relazionali (con un driver jdbc appropriato), cubi (tramite MDX), file piatti e endpoint API (compresi i connettori predefiniti alle più diffuse applicazioni cloud). Questo framework è estensibile e i clienti possono creare le proprie connessioni o utilizzare una connessione di terze parti, se disponibile.
Motore ETL (opzionale) – si tratta di un componente opzionale che i clienti possono utilizzare se hanno bisogno di trasformare ulteriormente i loro dati in una forma adatta all’analisi. I dati possono essere letti da qualsiasi fonte, combinati, trasformati e quindi ritrascritti in qualsiasi DBMS scrivibile da noi supportato. È disponibile un’ampia gamma di operazioni di trasformazione, tra cui l’unione dei dati, la divisione dei dati, la creazione di nuove colonne, la modifica dei tipi di dati, la sostituzione dei valori e così via. Inoltre, i clienti possono collegare un flusso di lavoro ETL a un modello di Data Science di terze parti per migliorare i dati con i risultati di un algoritmo predittivo. Attualmente supportiamo modelli esportati in formato pmml, nonché connessioni live a server R, H20.ai e AWS SageMaker. Il framework delle fasi ETL è estensibile e i clienti possono creare e inserire le proprie fasi ETL personalizzate.
Livello dei metadati – questo livello contiene tutte le informazioni necessarie sui dati a partire dai quali devono essere creati i report. Queste includono le strutture delle tabelle, le condizioni di join, i campi calcolati, la formattazione dei dati e così via. Questi dati vengono poi utilizzati dal Query Engine che genera query specifiche per il DB sotto forma di SQL, MDX o altre chiamate per interrogare dinamicamente la connessione dati live. I dati possono anche provenire da una Stored Procedure o da un SQL codificato a mano. A questo livello vengono applicati aspetti della sicurezza, tra cui l’applicazione di filtri di accesso e/o la sostituzione della fonte dei dati per supportare la segregazione logica o fisica dei dati in un ambiente multi-tenant.
Yellowfin Report – questo modulo è responsabile della richiesta di dati al Query Engine, del miglioramento di tali dati ove necessario e della generazione delle visualizzazioni richieste. Le Query Definitions contengono i dettagli necessari per definire esattamente i dati richiesti per produrre ogni report o visualizzazione. Esistono vari sotto-engine che eseguono ulteriori elaborazioni sui dati una volta restituiti dal motore di query:
- Motore di post-elaborazione – questo motore prende i dati grezzi da una query e li prepara per la presentazione. Questo include la combinazione di dati provenienti da fonti diverse, l’esecuzione di tabulazioni incrociate di dati, la conversione di tipi di dati, la formattazione dei dati e l’arricchimento dei dati mediante l’esecuzione di complesse post-elaborazioni. La post-elaborazione può includere l’esecuzione di calcoli statistici avanzati (come percentuale sul totale, StdDev, previsioni, ecc.) e il richiamo ad applicazioni di terze parti per arricchire i dati (ad esempio invocando un modello di data-science predittivo utilizzando lo stesso framework del motore ETL). Le funzioni di post-elaborazione sono estensibili e i clienti possono scrivere e includere le proprie funzioni per eseguire elaborazioni specifiche prima della visualizzazione dei dati.
- Motore di visualizzazione – questo motore genera i contenuti visibili per gli utenti, tra cui report, grafici, dashboard, presentazioni e storie. Questo framework è anche estensibile, ad esempio è possibile includere grafici Javascript e altri componenti UI personalizzati.
- Raw Data Provider – i set di dati restituiti dai report sono accessibili tramite chiamate API. I clienti possono eseguire elaborazioni personalizzate sui set di dati sottostanti prima che questi vengano presentati in una visualizzazione Yellowfin o in un elemento UI personalizzato sviluppato dal cliente.
- Cache dei dati – Yellowfin può essere configurato per memorizzare i dati nella cache al fine di velocizzare l’esperienza dell’utente finale. È possibile memorizzare nella cache una serie di dati, tra cui i dati effettivi del report, i valori dei filtri, i preferiti e così via. L’aggiornamento dei dati può essere programmato tramite lo scheduler di Yellowfin.
Livello dei contenuti – I contenuti possono essere consumati tramite l’applicazione Yellowfin dai browser più diffusi, dall’applicazione mobile nativa Yellowfin (IOS o Android) e i singoli componenti possono essere incorporati nelle applicazioni tramite chiamate API. In genere gli utenti interagiscono con le visualizzazioni di Yellowfin tramite una Dashboard, una Presentazione o una Storia – o una visualizzazione incorporata direttamente in un’applicazione di terze parti. Il livello di contenuto può essere ridisegnato e personalizzato per soddisfare le esigenze del cliente. Il livello dei contenuti offre altre funzionalità, tra cui
- Contenuti di terze parti – a partire dal prodotto Story, i clienti possono incorporare in Yellowfin visualizzazioni provenienti da applicazioni di BI di terze parti. I contenuti di Tableau, Qlik e PowerBI possono essere integrati e visualizzati insieme ai contenuti di Yellowfin.
- Timeline Feed – il timeline feed serve avvisi personalizzati e contenuti rilevanti per gli utenti tramite l’applicazione Yellowfin, l’app mobile o un’API REST.
Motore di pianificazione – contiene un motore di pianificazione flessibile per programmare lavori ETL, distribuzione di report, lavori di segnalazione e altre attività di sistema. Alcune attività programmate possono essere attivate, ad esempio in base al superamento di soglie predefinite.
Motore dei segnali – il motore dei segnali analizza automaticamente i dati per identificare gli eventi significativi e quindi genera avvisi personalizzati che vengono consegnati tramite il feed della timeline, sia nel client del browser che in quello mobile. I lavori dei segnali sono configurati e sfruttano il livello dei meta-dati e possono essere programmati per essere eseguiti con qualsiasi frequenza utilizzando il motore di pianificazione. Il motore dei segnali è complesso e contiene un motore di generazione di serie temporali, diversi algoritmi di rilevamento degli eventi, un motore di classificazione e personalizzazione e un motore di notifica.
Assisted Insights Engine – si tratta di un insieme di algoritmi che vengono invocati per generare automaticamente approfondimenti sui dati al volo. Questi approfondimenti sono accessibili attraverso l’interazione diretta dell’utente con una visualizzazione grafica, attraverso il processo di creazione dei report e anche per fornire spiegazioni più approfondite dietro ai segnali.
-
Architettura tecnica
Quali sono i componenti chiave dell’architettura della piattaforma Yellowfin?
Yellowfin è composto da un Application Server Java (che gira su Apache Tomcat) e da un Database Repository. Il database del repository può esistere su uno dei seguenti sistemi di database supportati: PostgreSQL, Microsoft SQL Server, MySQL, Oracle, DB2 o Ingres.
L’applicazione può essere scalata per ottenere una maggiore capacità e un failover clusterizzando più Application Server Yellowfin sullo stesso database del repository.
Server di applicazioni
Quale application server posso utilizzare per eseguire Yellowfin?
Yellowfin installerà un’istanza di Tomcat durante l’installazione. I clienti che desiderano utilizzare un Application Server Java di terze parti possono consumare Yellowfin come file WAR, da distribuire sull’infrastruttura esistente.
Tomcat dispone di diversi connettori che consentono l’integrazione con server web esterni per permettere a Yellowfin di essere esposto su un sito web o un portale esistente. Questi includono Apache, IIS e Nginx.
Ci sono componenti o librerie proprietarie esterne fornite con Yellowfin?
Con Yellowfin non vengono fornite librerie proprietarie.
Quali librerie open source vengono fornite con Yellowfin?
Yellowfin viene fornito con molte librerie open-source con licenza consentita. Un elenco completo di queste è documentato nella directory legale dell’installazione di Yellowfin.
I miei dati di reportistica vengono mai archiviati in Yellowfin?
Yellowfin memorizzerà temporaneamente i dati durante la visualizzazione di report e dashboard. Altre opzioni, non abilitate per impostazione predefinita, consentono di memorizzare nella cache i valori dei report e dei filtri nel database del Repository. Questo serve per scattare un’istantanea di un report e per permettere agli utenti di scegliere i valori dei filtri da un elenco a discesa. La cache dei dati dei report può anche memorizzare i dati in memoria. In questo modo il set di dati di una query di report viene memorizzato per essere riutilizzato entro un periodo di tempo configurabile.
Database del deposito
Dove sono conservati i dati di configurazione?
Tutti i dati di configurazione e i metadati, compresi gli utenti, i gruppi e le definizioni dei contenuti, sono memorizzati nel database del Repository in uno schema relazionale. Questo database viene creato al momento dell’installazione e può esistere in uno dei seguenti sistemi di database supportati: PostgreSQL, Microsoft SQL Server, MySQL, Oracle, DB2 o Ingres.
Come faccio a fare il backup dei dati di configurazione?
Un backup completo della configurazione di Yellowfin può essere effettuato eseguendo il backup del database del repository. I backup possono essere utilizzati per le istantanee periodiche o per spostare o clonare gli ambienti tra i sistemi. L’utilizzo di funzionalità di database, come il Log Shipping o il clustering, consente di eseguire il backup dei dati di configurazione in tempo reale e di garantire il failover e il disaster recovery.
-
Apertura ed estensibilità
Distribuisci ovunque
Quali sistemi operativi posso utilizzare?
Yellowfin può essere installato su desktop o laptop basati su Windows, Linux o Mac OSX per scopi di valutazione o formazione e installato su server basati su Windows, Linux o Mac OSX per scopi di valutazione, formazione e produzione.
In quali ambienti cloud posso distribuire?
Yellowfin funziona con tutti i principali provider di cloud, tra cui AWS, Azure, GCP e altri ancora.
Posso eseguire istanze di Yellowfin on premise?
Sì, puoi distribuire in sede o nel cloud.
Nessun Vendor Lock-in
Posso evitare di essere vincolato alla piattaforma Yellowfin?
ESCROW – ti garantisce l’accesso al codice sorgente della piattaforma in caso di insolvenza di Yellowfin.
Accesso al design dei tuoi contenuti e alle estensioni di codice (di tua proprietà) – anche se smetti di usare Yellowfin, puoi usare i ricchi contenuti visivi e le estensioni di codice delle tue app e dashboard per la reingegnerizzazione in un’altra piattaforma o tecnologia
I tuoi dati possono essere archiviati in un database di tua scelta, di tua proprietà e accessibile in ogni momento.Sarò vincolato a un database proprietario?
No, Yellowfin non ha un database proprietario o un database in-memory. Tutti i dati sono archiviati in sistemi di gestione di database di uso comune di tua scelta.
Di conseguenza, puoi accedere ai tuoi dati in qualsiasi momento e utilizzarli con altri strumenti, oppure spostare i tuoi dati in qualsiasi altro DBMS di tua scelta.Dovrò imparare un linguaggio di scripting proprietario?
No, Yellowfin non dispone di linguaggi di scripting proprietari per spostare i dati o creare visualizzazioni. Yellowfin utilizza solo linguaggi comuni del settore o funzionalità di drag and drop per tutti i suoi processi. Ad esempio, per creare un livello di metadati Yellowfin puoi usare il drag and drop della GUI o dell’SQL, oppure per la modalità Codice dei cruscotti puoi usare HTML, JavaScript e CSS.
Posso scegliere di ospitare Yellowfin in qualsiasi ambiente?
Con Yellowfin puoi distribuire on premise, nel tuo data center o sul cloud provider di tua scelta come AWS, Azure, Google, Oracle ecc.
Posso utilizzare il mio ambiente di data warehouse esistente?
Sì, Yellowfin si connette a molti DBMS e non ingerisce i dati in un formato proprietario. Quindi, se i tuoi dati sono già pronti e in un formato ottimizzato per la reportistica, non dovrai spostarli o lavorare ulteriormente sui tuoi dati. Basta collegarsi al tuo data warehouse e iniziare a creare contenuti.
API esposte
Che tipo di API espone Yellowfin?
Yellowfin dispone di due principali funzionalità API:
L’API JavaScript – utilizzata per incorporare i contenuti di report e dashboard in un’applicazione di terze parti
Web Services API – una ricca varietà di servizi utilizzati per automatizzare le attività amministrative, manipolare programmaticamente i contenuti come gli utenti, i permessi di sicurezza dei meta-dati o per integrare i contenuti in un’applicazione (web o mobile). Sono supportati sia servizi web SOAP che REST.Posso automatizzare i processi di Yellowfin?
È possibile automatizzare una serie di processi amministrativi utilizzando il livello dei servizi web.
Posso creare modelli di dati in Yellowfin automaticamente sulla base del mio schema?
Sì: il modello di meta-dati può essere manipolato direttamente utilizzando i servizi web, oppure i file di contenuto possono essere costruiti esternamente secondo lo standard concordato e importati in Yellowfin utilizzando il servizio web Import.
Estensibilità
Come posso estendere le funzionalità di Yellowfin?
Yellowfin offre una serie di modi per estendere le nostre funzionalità. Puoi creare flussi di lavoro ed esperienze utente personalizzate, aggiungere estensioni attraverso i nostri plug-in e molto altro ancora. Per una panoramica completa di ciò che è possibile fare , consulta la sezione Estendere Yellowfin.