Yellowfin Evaluation Guide
Yellowfin is used for both enterprise analytics and embedded analytics use cases and for building bespoke analytical applications. Use this guide to ensure Yellowfin is the right technical fit for your requirements.

Aperçu de l’architecture
-
In this section
Updated 3 juin 2020 -
Aperçu de l'architecture
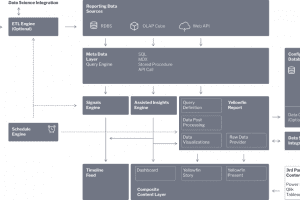
Quels sont les principaux éléments de l’architecture Yellowfin ?

Vous trouverez ci-dessous une description des principaux éléments fonctionnels de l’architecture Yellowfin.
Base de données de configuration – stocke toutes les données de configuration requises par Yellowfin, y compris les informations sur les utilisateurs, la sécurité, les sources de données et le contenu créé dans Yellowfin. Le contenu créé comprend les définitions des rapports, des graphiques, des tableaux de bord, des présentations et des histoires. Peut être implémentée dans une variété de bases de données relationnelles, y compris SQLServer, MySQL et Oracle.
Reporting des sources de données – Yellowfin se connecte en direct à une grande variété de sources de données, y compris les bases de données relationnelles et non relationnelles les plus courantes (avec un pilote jdbc approprié), les cubes (via MDX), les fichiers plats et les points d’extrémité API (y compris les connecteurs prêts à l’emploi vers les applications cloud les plus courantes). Ce cadre est extensible et les clients peuvent créer leurs propres connexions ou utiliser une connexion tierce si elle est disponible.
Moteur ETL (optionnel ) – il s’agit d’un composant optionnel que les clients peuvent utiliser s’ils ont besoin de transformer davantage leurs données sous une forme adaptée à l’analyse. Les données peuvent être lues à partir de n’importe quelle source, combinées, transformées, puis écrites dans n’importe quel SGBD accessible en écriture que nous prenons en charge. Une grande variété d’étapes de transformation est disponible, y compris la fusion des données, la division des données, la création de nouvelles colonnes, la modification des types de données, le remplacement des valeurs, etc. En outre, les clients peuvent connecter un flux de travail ETL à un modèle Data Science tiers pour améliorer les données avec les résultats d’un algorithme prédictif. Nous prenons actuellement en charge les modèles exportés au format pmml, ainsi que les connexions en direct aux serveurs R, H20.ai et AWS SageMaker. Le cadre des étapes ETL est extensible et les clients peuvent construire et ajouter leurs propres étapes ETL personnalisées.
Couche de métadonnées – cette couche contient toutes les informations nécessaires sur les données à partir desquelles les rapports doivent être élaborés. Il s’agit notamment de la structure des tables, des conditions de jointure, des champs calculés, du formatage des données, etc. Ces données sont ensuite utilisées par le moteur de requête qui génère des requêtes spécifiques à la base de données sous la forme d’appels SQL, MDX ou autres pour interroger dynamiquement la connexion de données en direct. Les données peuvent également provenir d’une procédure stockée ou d’un code SQL manuel. Des aspects de la sécurité sont appliqués à ce niveau, notamment l’application de filtres d’accès et/ou la substitution de sources de données afin de soutenir la ségrégation logique ou physique des données dans un environnement multi-locataire.
Yellowfin Report – ce module est chargé de demander des données au moteur de requête, d’améliorer ces données si nécessaire et de générer les visualisations demandées. Les définitions des requêtes contiennent les détails nécessaires sur les données requises pour produire chaque rapport ou visualisation. Il existe plusieurs sous-moteurs qui effectuent des traitements supplémentaires sur les données une fois qu’elles sont renvoyées par le moteur de requête :
- Moteur de post-traitement – ce moteur prend les données brutes d’une requête et les prépare pour la présentation. Il s’agit notamment de combiner des données provenant de sources disparates, d’effectuer des tableaux croisés, de convertir les types de données, de formater les données et d’enrichir les données en effectuant un post-traitement complexe. Le post-traitement peut inclure l’exécution de calculs statistiques avancés (tels que le pourcentage du total, StdDev, les prévisions, etc.) et l’appel à des applications tierces pour enrichir les données (telles que l’invocation d’un modèle prédictif de science des données utilisant le même cadre que le moteur ETL). Les fonctions de post-traitement sont extensibles et les clients peuvent écrire et inclure leurs propres fonctions pour effectuer un traitement spécifique avant l’affichage des données.
- Moteur de visualisation – ce moteur génère le contenu visible pour les utilisateurs, y compris les rapports, les graphiques, les tableaux de bord, les présentations et les histoires. Ce cadre est également extensible, par exemple les graphiques Javascript peuvent être inclus ainsi que d’autres composants d’interface utilisateur personnalisés.
- Fournisseur de données brutes – les ensembles de données renvoyés par les rapports sont accessibles via des appels API. Les clients peuvent effectuer un traitement personnalisé sur les ensembles de données sous-jacents avant que les données ne soient présentées dans une visualisation Yellowfin ou un élément d’interface utilisateur personnalisé développé par le client.
- Cache de données – Yellowfin peut être configuré pour mettre en cache des données afin d’accélérer l’expérience de l’utilisateur final. Une variété de données peut être mise en cache, y compris les données de rapport actuelles, les valeurs de filtre, les favoris, etc. Les rafraîchissements de données peuvent être programmés via le planificateur de Yellowfin.
Couche de contenu – Le contenu peut être consommé via l’application Yellowfin à partir des navigateurs les plus courants, à partir de l’application mobile native de Yellowfin (IOS ou Android) et des composants individuels peuvent être intégrés dans des applications via des appels API. Les utilisateurs interagissent généralement avec les visualisations de Yellowfin par le biais d’un tableau de bord, d’une présentation ou d’une histoire – ou d’une visualisation intégrée directement dans une application tierce. La couche de contenu peut être remodelée et personnalisée pour répondre aux besoins du client. D’autres capacités sont disponibles au niveau de la couche de contenu, notamment:-
- Contenu de tiers – à partir du produit Story, les clients peuvent intégrer dans Yellowfin des visualisations provenant d’applications de BI de tiers. Le contenu de Tableau, Qlik et PowerBI peut être intégré et visualisé en même temps que le contenu de Yellowfin.
- Flux chronologique – le flux chronologique fournit des alertes personnalisées et du contenu pertinent aux utilisateurs via l’application Yellowfin, l’application mobile ou via une API REST.
Moteur de planification – contient un moteur de planification flexible pour programmer les travaux ETL, la distribution des rapports, les travaux de signalisation et d’autres tâches du système. Certaines tâches programmées peuvent être déclenchées, par exemple en cas de dépassement de seuils prédéfinis.
Moteur de signaux – le moteur de signaux analyse automatiquement les données pour identifier les événements importants, puis génère des alertes personnalisées qui sont diffusées via le flux de la ligne du temps, soit dans le client navigateur, soit dans le client mobile. Les tâches liées aux signaux sont configurées dans la couche de métadonnées et peuvent être programmées à n’importe quelle fréquence à l’aide du moteur de programmation. Le moteur de signaux est complexe et contient un moteur de génération de séries temporelles, plusieurs algorithmes de détection d’événements, un moteur de classement et de personnalisation, et un moteur de notification.
Moteur d’analyse assistée – il s’agit d’un ensemble d’algorithmes invoqués pour générer automatiquement des analyses de données à la volée. Ces informations sont accessibles par l’interaction directe de l’utilisateur avec la visualisation d’un graphique, par le processus de création d’un rapport et également pour fournir des explications plus approfondies sur les signaux.
-
Architecture technique
Quels sont les éléments clés de l’architecture de la plateforme Yellowfin ?
Yellowfin se compose d’un serveur d’application Java (qui fonctionne sur Apache Tomcat) et d’une base de données de dépôt. La base de données du référentiel peut exister sur l’un des systèmes de base de données suivants : PostgreSQL, Microsoft SQL Server, MySQL, Oracle, DB2 ou Ingres.
L’application peut être mise à l’échelle pour une plus grande capacité et un basculement en mettant en cluster plusieurs serveurs d’application Yellowfin par rapport à la même base de données de référentiel.
Serveur d'application
Quel serveur d’application puis-je utiliser pour exécuter Yellowfin ?
Yellowfin installera une instance de Tomcat lors de l’installation. Les clients qui souhaitent utiliser un serveur d’application Java tiers peuvent consommer Yellowfin sous la forme d’un fichier WAR, à déployer sur leur infrastructure existante.
Tomcat a plusieurs connecteurs qui permettent l’intégration avec des serveurs Web externes pour permettre à Yellowfin d’être exposé sur un site Web ou un portail existant. Cela inclut Apache, IIS et Nginx.
Y a-t-il des composants ou des bibliothèques propriétaires externes livrés avec Yellowfin ?
Aucune bibliothèque propriétaire n’est livrée avec Yellowfin.
Quelles sont les bibliothèques open source livrées avec Yellowfin ?
Yellowfin est livré avec de nombreuses bibliothèques open-source sous licence. Une liste complète de ces bibliothèques est documentée dans le répertoire légal de l’installation de Yellowfin.
Mes données de reporting sont-elles toujours conservées dans Yellowfin ?
Yellowfin stockera temporairement les données en mémoire pendant la visualisation des rapports et des tableaux de bord. D’autres options, qui ne sont pas activées par défaut, permettent aux rapports et aux valeurs des filtres d’être mis en cache dans la base de données du référentiel. Cela permet de prendre un instantané d’un rapport et de permettre aux utilisateurs de choisir des valeurs de filtre à partir d’une liste déroulante. Le cache de données de rapport peut également stocker des données en mémoire. Il stocke l’ensemble des données d’une requête de rapport pour les réutiliser dans un délai configurable.
Base de données du référentiel
Où sont stockées mes données de configuration ?
Toutes les données de configuration et les métadonnées, y compris les utilisateurs, les groupes et les définitions de contenu, sont stockées dans la base de données du référentiel selon un schéma relationnel. Cette base de données est créée lors de l’installation et peut exister dans l’un des systèmes de base de données suivants : PostgreSQL, Microsoft SQL Server, MySQL, Oracle, DB2 ou Ingres.
Comment sauvegarder mes données de configuration ?
Une sauvegarde complète de la configuration de Yellowfin peut être effectuée en sauvegardant la base de données du référentiel. Les sauvegardes peuvent être utilisées pour des instantanés périodiques, ou pour déplacer ou cloner des environnements entre systèmes. L’utilisation d’une fonctionnalité de base de données, comme le Log Shipping, ou le clustering permet de sauvegarder les données de configuration en temps réel, et d’assurer le basculement et la reprise après sinistre.
-
Ouverture et extensibilité
Déployer partout
Quels sont les systèmes d’exploitation dans lesquels je peux me déployer ?
Yellowfin peut être installé sur un ordinateur de bureau ou un ordinateur portable fonctionnant sous Windows, Linux ou Mac OSX à des fins d’évaluation ou de formation et installé sur des serveurs fonctionnant sous Windows, Linux ou Mac OSX à des fins d’évaluation, de formation et de production.
Quels sont les environnements en nuage dans lesquels je peux me déployer ?
Yellowfin fonctionnera avec tous les principaux fournisseurs de cloud, notamment AWS, Azure, GCP et bien d’autres encore.
Puis-je faire fonctionner des instances de Yellowfin sur site ?
Oui, vous pouvez déployer sur site ou dans le nuage.
Pas de verrouillage des fournisseurs
Puis-je éviter d’être lié à la plateforme Yellowfin ?
ESCROW – vous donne accès au code source de la plateforme en cas d’insolvabilité de Yellowfin
Accès à la conception de votre contenu et aux extensions de code (qui vous appartiennent) – même si vous cessez d’utiliser Yellowfin, vous pouvez utiliser le contenu visuel riche et les extensions de code de vos applications et tableaux de bord en vue d’une réingénierie sur une autre plateforme ou technologie.
Vos données peuvent être stockées dans la base de données de votre choix, dont vous êtes propriétaire et à laquelle vous avez accès à tout moment.Serai-je enfermé dans une base de données propriétaire ?
Non, Yellowfin n’a pas de base de données propriétaire ou de base de données en mémoire. Toutes les données sont stockées dans des systèmes de gestion de base de données courants de votre choix.
Par conséquent, vous pouvez accéder à vos données à tout moment et les utiliser avec d’autres outils, ou déplacer vos données dans tout autre système de gestion de base de données de votre choix.Devrai-je apprendre un langage de script propriétaire ?
Non, Yellowfin n’a pas de langages de script propriétaires pour déplacer des données ou construire des visualisations. Yellowfin n’utilise que des langages industriels courants ou des fonctionnalités de glisser-déposer pour tous ses processus. Par exemple, pour créer une couche de métadonnées Yellowfin, vous pouvez utiliser une interface graphique ou SQL par glisser-déposer, ou pour le mode Code sur les tableaux de bord, utiliser HTML, JavaScript et CSS.
Puis-je choisir d’héberger Yellowfin dans n’importe quel environnement ?
Avec Yellowfin, vous pouvez déployer sur site, dans votre propre centre de données ou chez le fournisseur de services en nuage de votre choix, comme AWS, Azure, Google, Oracle, etc.
Puis-je utiliser mon environnement d’entrepôt de données existant ?
Oui, Yellowfin se connecte à de nombreux SGBD et n’ingère pas de données dans un format propriétaire. Ainsi, si vos données sont déjà préparées et dans un format optimisé pour le reporting, vous n’aurez pas à les déplacer ou à effectuer d’autres travaux sur vos données. Il vous suffit de vous connecter à votre entrepôt de données et de commencer à créer du contenu.
API exposées
Quel type d’API Yellowfin expose-t-il ?
Yellowfin dispose de deux capacités API principales :
L’API JavaScript – utilisée pour intégrer le contenu des rapports et des tableaux de bord dans une application tierce
Web Services API – une grande variété de services utilisés pour automatiser les tâches administratives, manipuler de manière programmatique le contenu tel que les utilisateurs, les autorisations de sécurité des métadonnées, ou pour intégrer le contenu dans une application (application web ou application mobile). Les services web SOAP et REST sont pris en charge.Puis-je automatiser les processus de Yellowfin ?
Oui, toute une série de processus administratifs peuvent être automatisés à l’aide de la couche des services Web.
Puis-je créer automatiquement des modèles de données dans Yellowfin sur la base de mon schéma ?
Oui – le modèle de métadonnées peut être manipulé directement à l’aide de services web, ou des fichiers de contenu peuvent être créés à l’extérieur selon la norme convenue et importés dans Yellowfin à l’aide du service web d’importation.
Extensibilité
Comment puis-je étendre les fonctionnalités de Yellowfin ?
Yellowfin offre de nombreuses possibilités d’extension de ses fonctionnalités. Vous pouvez créer des flux de travail et des expériences utilisateur personnalisés, ajouter des extensions par le biais de nos modules d’extension et bien plus encore. Pour une gamme complète de ce qui est possible , voir Extension de Yellowfin.